
はじめに
三菱総研DCS 技術戦略部テクニカルラボグループの日野です。
東京デジタルイノベーション2020でデモンストレーションを行ったサンプルアプリケーションの内容について、これから3回に分けてご紹介します。アプリケーションの概要は前回の記事をご参照ください。
第1回 デモアプリの概要
第2回 来訪者の動線可視化(本記事)
第3回 来訪者の人数計測
第4回 リーフレットの残量計測
本記事では、来訪者の動線可視化を行った箇所の実装について解説します。
展示スペースの動線可視化アプリケーションの概要
動線可視化アプリケーションでは、ブース上部に設置したUSBカメラの画像をもとに人物領域を検出し、その人物はどのパネルの前に立っているのか、どれくらい滞在していて、どういう経路を歩いてきたのかを可視化します。
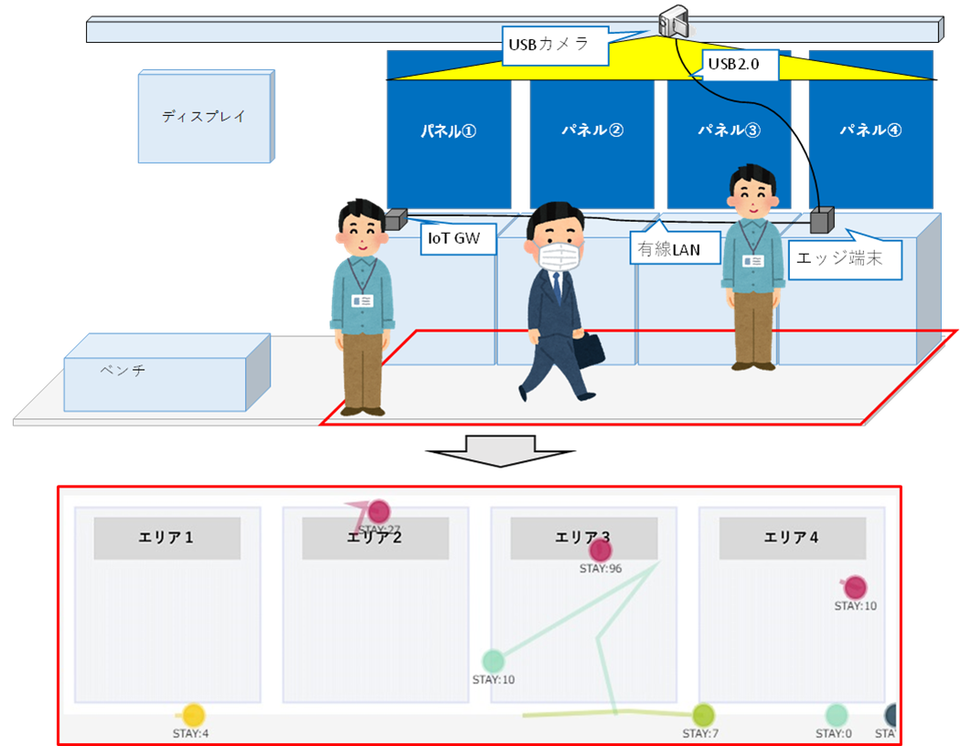
図1.アプリ概要
システム構成および使用デバイスは以下の通りです。
全体のシステム構成のうち主に以下のデバイス(赤く囲んだ箇所)で処理を行っています。
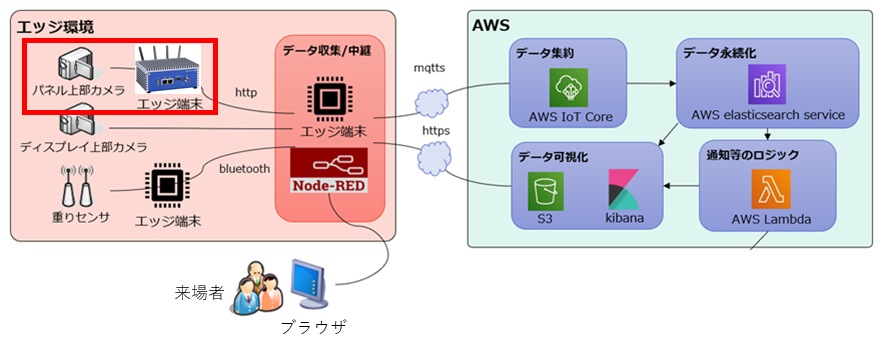
図2.システム構成
表1.使用デバイス
| 種類 | 製品名 | 備考 |
| USBカメラ | サンワサプライ CMS-V43BK | 設置可能な高さに制限があったため、カメラ1台でもブースが画角に収まるように広角(150°)カメラを使用しました。 |
| エッジ端末 | Edge AI Box Indoor EHC-J2-301 | CPU:ARM Cortex-A57@2Ghz+NVIDIA Denver2@2GHz GPU:NVIDIA Pascal 256 CUDA cores メモリ:8GB 128-bit LPDDR@1866 MHz onboard |
処理概要
カメラ画像から動線可視化を行う際には、以下のステップに分けて処理を行っています。
①人物領域の検出
②人物のトラッキング
③座標データの変換
④座標データ、IDデータをIoTゲートウェイ経由でAWSに送信
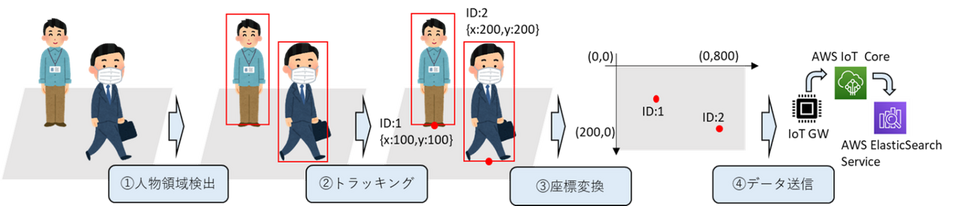
図3.処理概要
処理詳細
①人物領域の検出
カメラから取得した画像データから人物領域の検出を行う上では、検出速度と精度で優れた画像認識モデルの一つであるYolo v3を用いました。
Yolo v3:入力画像をグリッド分割し,領域ごとにバウンディングボックスとクラス確率を求めることで速度と精度を向上させた物体認識手法
また、USBカメラからリアルタイムで画像認識を行うにあたって、処理速度をできる限り向上させる必要があったため、NVIDIA社が提供しているメディアストリーム開発用フレームワークである、DeepStreamSDKも同時に利用しました。
DeepStream SDKを使うことで以下の恩恵を受けることができます。
- GPUや専用ハードウェアを用いた動画のエンコード/デコード高速化
- 高スループット推論のためのマルチGPU、マルチストリーム、バッチ処理のサポート
- Deep Learningを用いた物体検出、画像分類を、GPUおよびTensorRTを用いて高速化
- Kafka、MQTT、およびAMQPとのプラグインを用いた簡易な連携
そのうえで、処理速度を上げるための工夫として以下を行いました。
- CNNの畳込演算をFP32(32ビット幅の浮動小数点演算)ではなくFP16精度で演算(DeepStreamの機能)
- 推論を行う際の画像の解像度を精度が大きく下がらない範囲で下げる。
- 物体検出処理を数フレームに一度にする
※人物検出していないフレームにおいては、後述するトラッキング処理を行っています。
②人物のトラッキング
人物の滞在時間を取得したり、動線を可視化するにあたっては、あるフレームで検出した人物領域と、その次のフレームで検出した人物領域がどう紐づいているのかを判断する必要があり、その紐づけを行うためにトラッキング処理を行います。
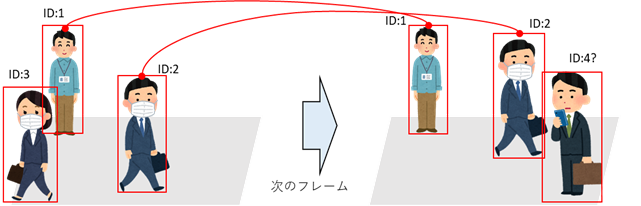
図4.トラッキングのイメージ
また、トラッキングを行うことで、処理の重い画像認識を行わなくても画像的な特徴から物体の動きを予測することができるため、パフォーマンスの向上という点でも重要なポイントとなります。ただし、トラッキングでの座標予測は時間経過によるずれが大きいため、物体検出を数フレームに一度行い補正を行っています。
DeepStream SDKではプラグインとして複数のトラッキングアルゴリズムが提供されていますが、今回はその中のIoU(Intersection over Union)アルゴリズムを採用しました。IoUは、フレーム間での人物領域の重なりが最大になる領域を、同一オブジェクトとして紐づけを行うアルゴリズムです。
③座標データの変換
人物領域からその人の立ち位置を取得するにあたり、矩形領域の底面の中央の点を立ち位置とみなすようにしました。
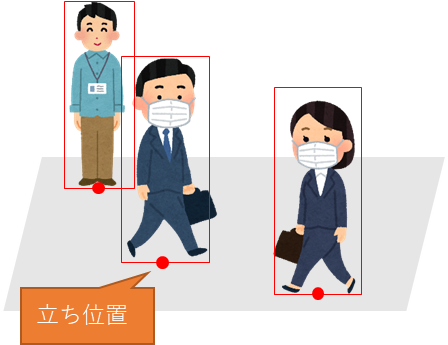
図5.立ち位置取得のイメージ
また、求めた人物の立ち位置の座標をWebページ上で可視化するにあたり、HTMLページ上のキャンバスに合わせた座標の変換処理や、斜めから撮影した画像内座標を、俯瞰座標へ変換します。その際は、OpenCV内でも関数として提供されているホモグラフィ変換を利用することで、簡単に実装可能です。
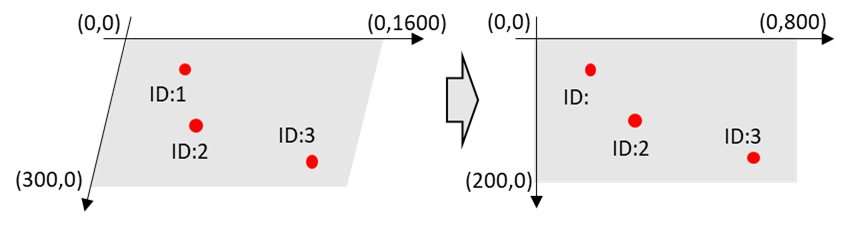
図6.座標変換のイメージ
(※実際は単純な平行四辺形から長方形への変換ではありません)
以上の一連の処理を行うことで、USBカメラ画像から以下のようなイメージで座標データを取得できます。
イメージ画像では立ち位置座標を、画像内右上のグラフに赤い点で表示しています

図7.処理イメージ
④座標データ、IDデータをIoTゲートウェイ経由でAWSに送信
座標データはその後IoTゲートウェイであるエッジ端末上のNode-RedにWebSocketを用いて送信し、順次MQTTS通信でAWSへデータを送信、AWS Elasticsearch Serviceへデータを永続化します。
AWS Elasticsearch Service上のデータは、S3上にデプロイしたシングルページアプリケーションで可視化します。以上の処理を行うことで、会場で撮影したデータを数秒~十数秒後にWebブラウザ上に表示することができます。
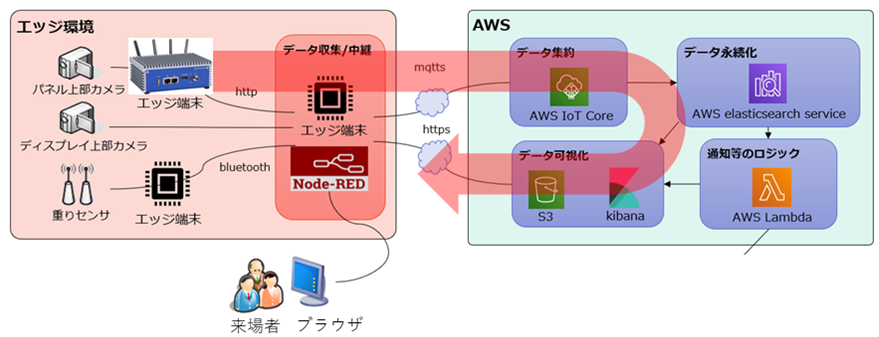
図8.データの流れ
まとめ
以下、個別で苦労した点や反省点になります。
苦労した点
- DeepStreamの起動に30分程度かかり、開発に時間がかかる。
- DeepStreamで独自のロジックを追加する際に、CUDAを使う関係上メモリエラーが発生することがあり、知見がない場合にメモリダンプからのデバッグが難しい。(そのため今回は、DeepStreamでの推論処理完了後はすぐにローカルのメッセージキューにキューイングし、座標変換などの推論以外のロジックは別のPythonプロセスで実装しました。)
反省点
- 展示会という過密状態での人物の重なりが想定以上に多かった。
そのため、トラッキングが途中で外れるなどが多発し、追跡の精度が低下した。 - 処理結果がWeb画面上に表示されるまでに最大十数秒程度のラグがあり、体感の人物位置とデモ画面を見た際の人物位置に差があるように感じた。(デモとしてはWebアプリケーションではなく、ローカルの処理結果を表示したほうが良かった。)
今回はイベントで展示したIoTデモアプリケーションのうち、展示スペースでの動線可視化アプリケーションの詳細について掘り下げて説明しました。
次回は引き続き、イベントスペースでの人数計測機能について説明してきます。
