
はじめに
三菱総研DCS デジタル企画推進部の桃井です。今回は当社で実施している自然言語処理技術検証の取り組みについてご紹介します。
また、この取り組みはDCSの研究開発活動の一環となります。研究開発活動の詳細は「DCSの研究開発活動についてご紹介します」にてご覧いただけます。
-
目次
- 背景・目的
- 固有表現抽出モデルの学習
- 後処理と集計
- まとめと今後の課題
- 少量のデータセットを作成し、固有表現抽出モデルを作成しました。
- 誤抽出された単語は文書間における出現頻度が低く、それを元に足切りができるため、適合率よりは再現率の方を重視してもよいかもしれません。
- 抽出処理は社内のサーバ上でCPUを使い実行しています。現段階では処理時間に問題は無いですが、今後分析対象の文書が増えた場合には、ALBERTやDistilBERTなどの軽量なモデルの使用も検討する必要がありそうです。
[1] Hugging Face:"What is Token Classification?",https://huggingface.co/tasks/token-classification
[2] 金融庁:"EDINET",https://disclosure2.edinet-fsa.go.jp/WEEK0010.aspx
[3] doccano:"doccano/doccano",https://github.com/doccano/doccano
[4] Hugging Face:"huggingface/transformers",https://github.com/huggingface/transformers
[5] Tohoku NLP Group:"cl-tohoku/bert-japanese",https://github.com/cl-tohoku/bert-japanese
[6] chakki:"chakki-works/seqeval",https://github.com/chakki-works/seqeval
[7] Elastic:"Synonym token filter | Elasticsearch Guide [8.6]",https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-synonym-tokenfilter.html -

背景・目的
アカウントプランの作成や市場の調査など、他社のリサーチを行う業務があります。これらを人手で行う場合、時間の都合で一部の企業しか調査できないことや、調査内容の質が作業者の能力に依存するといったことが課題として挙げられます。そこで、自然言語処理(*)技術を適用することで、それらの業務の一部を自動化できないかと考えました。
今回はリサーチ業務の中でも、IR資料の文章を元に、他社が取り組んでいる技術をまとめる作業を自動化の対象としました。(図1)
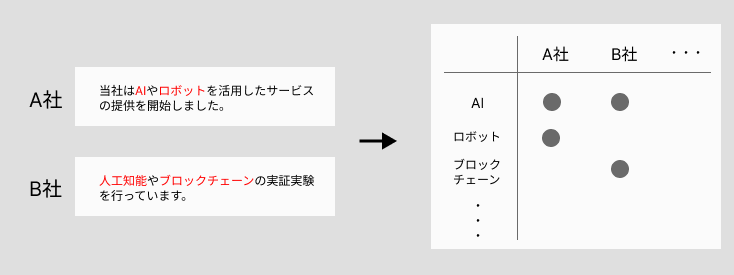
図1.調査の概略
文章中からキーワードを抜き出す方法として、事前に定義した辞書にマッチする文字列を抽出する方法があります。しかし、この方法は辞書の作成コストや、技術動向を追って新語を追加していくメンテナンスコストの高さが課題となります。一方で、近年進化を続けている自然言語処理ならば、前後の文脈を考慮した推論を行い、辞書に頼らずにキーワードを抽出することが可能であると考えられます。
(*) 自然言語処理とは
自然言語処理とは、自然言語(日本語や英語など、私たちが日常的に使う言語)をコンピュータで処理する技術のことを指します。近年はAIを用いた分析技術が発展してきており、特にBERT(Google)やGPT-3(OpenAI)といった高度な技術の登場により従来技術で実現が難しかった処理が実現可能となってきています。
固有表現抽出モデルの学習
BERTの事前学習済みモデルを固有表現抽出タスクとしてfine-tuningすることで、文章中から技術キーワードを自動抽出します。fine-tuningとは解きたいタスクの教師データを用いて事前学習済みモデルを再学習する手法で、比較的少ない教師データでも高い精度のモデルを作成することが可能になります。処理の流れは図2のようになります。抽出後はデータベースに格納し、集計クエリの実行や別のアプリからの参照ができるようにします。
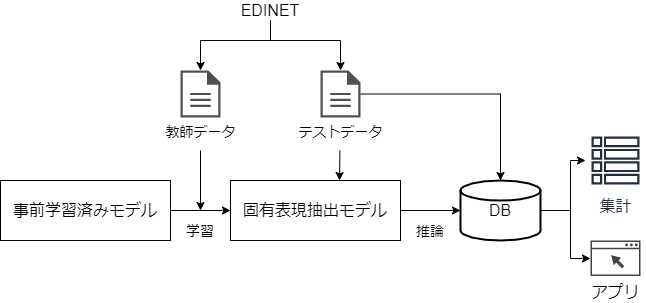
図2.処理の流れ
固有表現抽出とは
固有表現抽出とは、テキスト中の固有表現を抽出して適切なラベルを特定するタスクです。ここで言う「固有表現」とは、人名や地名、時間表現や数量、ある分野特有の専門用語などを指します。機械学習を用いた系列ラベリングの一種であり、辞書や教師データに現れない単語も文脈(系列)を元に認識することができるというメリットがあります。
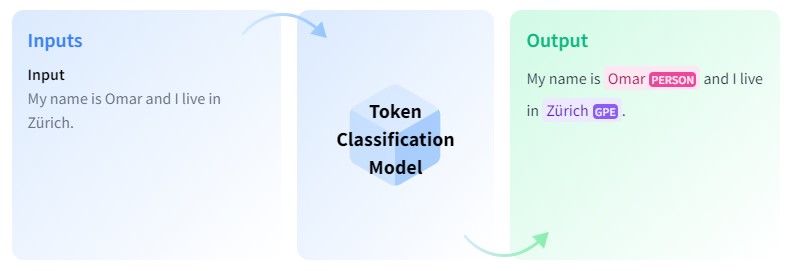
図3.固有表現抽出のイメージ(出典: Hugging Face[1])
データセットの作成
有価証券報告書には様々な内容が記載されていますが、その中から「研究開発活動」のセクションの文章を分析対象とします。情報通信業の企業を中心に、60件の有価証券報告書をEDINET[2]からダウンロードし、アノテーション(データへのタグ付け)を行いました。ラベルは「技術キーワード」のみで、固有表現抽出で一般的にラベリングされる日付や人名などは分類しません。アノテーション作業にはOSSのアノテーションツールであるdoccano[3]を使用しました。
モデルの学習
モデルの学習にはHuggingfaceのtransformers[4]を使用したのですが、データセットはIOB形式で渡す必要がありました。doccanoからエクスポートされるファイルは文字列のスパンの指定により固有表現を表現する形式のため、IOB形式への変換を行ってからモデルに渡します。(図4)
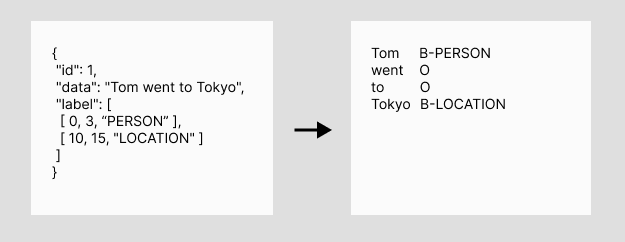
図4.アノテーションデータの変換
事前学習済みモデルには東北大学のcl-tohoku/bert-base-japanese-v2[5]を使用し、学習率は5e-5、バッチサイズは8、エポック数は10としました。 データセットは訓練データとテストデータを8:2で分割した後、訓練データをさらに5分割して交差検証を行いました。最後にテストデータに対する精度の平均を求めて最終的な精度としました。評価には、系列ラベリングに対する評価のフレームワークであるseqeval[6]を使用しました。精度を表1に、抽出結果の例を表2に示します。
表1.結果
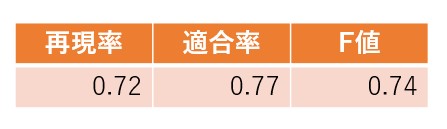
表2.抽出例
 また、テストデータとは別に他業種の文章を用意し、学習データに無い業種の専門用語も抽出できるか試してみました。これらの文章に対しても文脈を汲み取りキーワードを抽出することができ、ある程度の汎用性が確認できました。(表3)
また、テストデータとは別に他業種の文章を用意し、学習データに無い業種の専門用語も抽出できるか試してみました。これらの文章に対しても文脈を汲み取りキーワードを抽出することができ、ある程度の汎用性が確認できました。(表3)
表3.抽出例(他業種)

後処理と集計
キーワードの名寄せ
キーワードの抽出後は、オープンソースの全文検索エンジンであるElasticsearchに元の文章と共に格納します。ElasticsearchにはSynonym Token Filter[7]という類義語の名寄せ機能があるため、例えば「AI」と「人工知能」を同じ単語として集計できるようになります。 名寄せには辞書の作成が必要になりますが、ウェブ上のテキストからパターンマッチで収集した辞書と、人手で整備した辞書を用いて簡易的な名寄せができるようにしました。
※Elasticsearchにおける名寄せの様子
・filterで使用する同義語辞書
人工知能=>AI
・検索クエリ
※インデックスには上記filterを組み込んだanalyzerが設定済みのものとします。
GET /index_name/_search
{
"query": {
"terms": {
"filed_name": ["ai"]
}
},
"_source": {
"includes": ["field_name"]
}
}
・クエリの実行結果
「AI」で検索すると「人工知能」が含まれるドキュメントも返ってきます。
{
"took" : 5,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "index_name",
"_id" : "pFXJJIEBBJul9D6-kzI_",
"_score" : 1.0,
"_source" : {
"field_name" : [
"ai"
]
}
},
{
"_index" : "index_name",
"_id" : "yFbdJIEBBJul9D6-hU14",
"_score" : 1.0,
"_source" : {
"field_name" : [
"人工知能"
]
}
}
]
}
}
集計
一部の企業を抜粋して、キーワード抽出処理と名寄せを行い集計した結果が表4になります。(軸となるキーワードは一部のみ抜粋し、企業名は置き換えています) どの企業がどんな技術に取り組んでいるのかを表すマトリクスを作ることができました。元の文章も保存してあるため、抽出元となるデータソースを確認することも可能です。
表4.集計例

