
三菱総研DCS産業・公共企画部の帆足です。
本記事(後編)では、主にSnowflake単体での機能と実装内容をご紹介します。
(前編ではデータ共有方法をご紹介しています。詳細はこちら)
では後編、参りましょう!
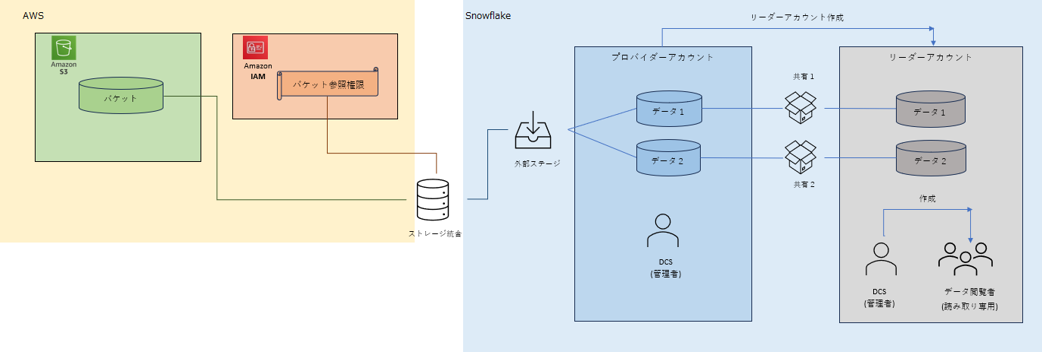
全体構成図(再掲)
構築したデータレイクの全体像を再掲いたします。
前編にてS3にあるデータをリーダーアカウントまで共有したため、今回はその共有されたデータを扱ううえでの設定内容をご紹介します。
コンピュートリソースの管理
仮想ウェアハウスの概要
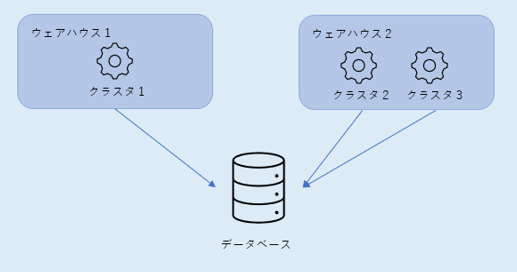
Snowflakeの大きな特徴として、コンピュートとストレージが分離している点があります。
コンピュートとはクエリ実行時のエンジン的なもので、「仮想ウェアハウス」と呼ばれます(以下、ウェアハウスと呼称します)。ウェアハウスに内蔵する「クラスタ」にて、クエリの処理を実行します。各ウェアハウスから全ストレージ(=データベースなど)にアクセスでき、独立して拡張可能です。なので、目的別に専用のウェアハウスを割り当てる(データエンジニアリング用、データアナリティクス用...etc)といったこともできます。また、ウェアハウスごとにアクセス可能なテーブルを権限割当できるので、あるテーブルがメンテ中ならデータアナリティクス用は触らせないようにする~といったことも可能です。
サービスを止めることなく臨機応変に性能拡張できる点は非常に便利!と思います。
(参考)ウェアハウスの概要 | Snowflake Documentation
クラスタのオートスケーリング
基本、各ウェアハウスの性能はクラスタの性能に依存する、といっても過言ではないです。
クラスタの性能はUIから簡単に設定・変更できます。
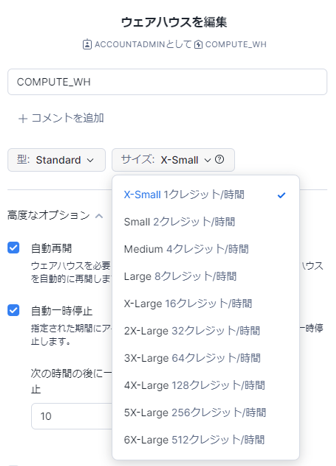
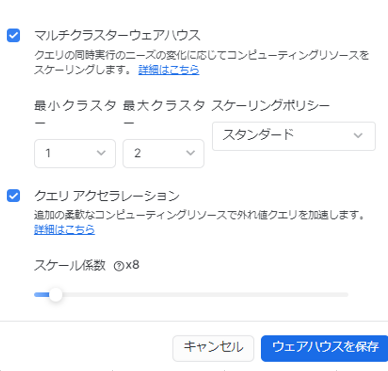
上図が主な設定内容です。
サイズが大きくなればなるほど性能が上がる仕組み。直感的に理解できるので良いですね!
また、クラスタ数を最小1/最大2にすると、デフォルト1つ/クエリが混雑してくると2つにオートスケーリングすることができます。今回においても、データ閲覧者のクエリが集中した場合を鑑み、オートスケーリングを導入しました。
リソースモニターによる監視
ズバリ、Snowflakeの「お金かかるポイント」 はコンピュート(=どれだけウェアハウスを使用したか)です。ストレージにもお金はかかりますが、1TBごとの定額制でコンピュートと比較するとお手頃な印象です。一方、ウェアハウスは使用時間に応じて課金されます。そうしたお金面でのモニタリングをするサービスとして、リソースモニターがあります。
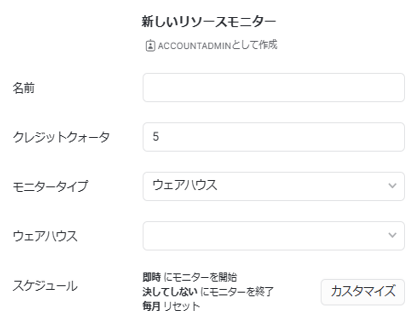
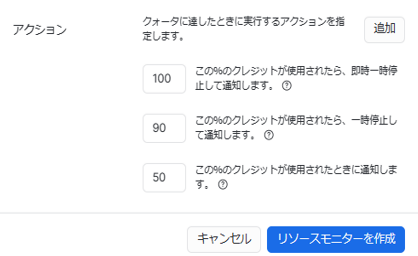
上のように、UIから設定可能です。
対象はアカウント全体か個々のウェアハウス単位かで選べます。クレジットクォータに基準となるクレジット数を入れておき、何%に達すれば通知/一時停止/即時一時停止するかを設定できます。(一時停止と即時一時停止の違いは、閾値超えた瞬間に実行中のクエリを完了させるか否かです)クレジット消費集計のリセットタイミングを指定できるため、毎月100クレジットに抑えたいな~という時は「毎月リセット」にすればOKです。
今回は日次/月次で以下のように作成しました。
- 日次:通知のみ
- 月次:通知、一時停止、即時一時停止
権限の管理
データ閲覧者はその名の通りデータを閲覧できればよく、データ変更などができるような状態は好ましくありません。では、どのように管理していけばよいでしょうか?
まずSnowflakeの権限周りから整理します。
ロール/権限周りのイメージ
Snowflakeは「ユーザのできること」を細かく管理できます。
用語として、アカウント/ユーザ/ロール/権限が登場します。
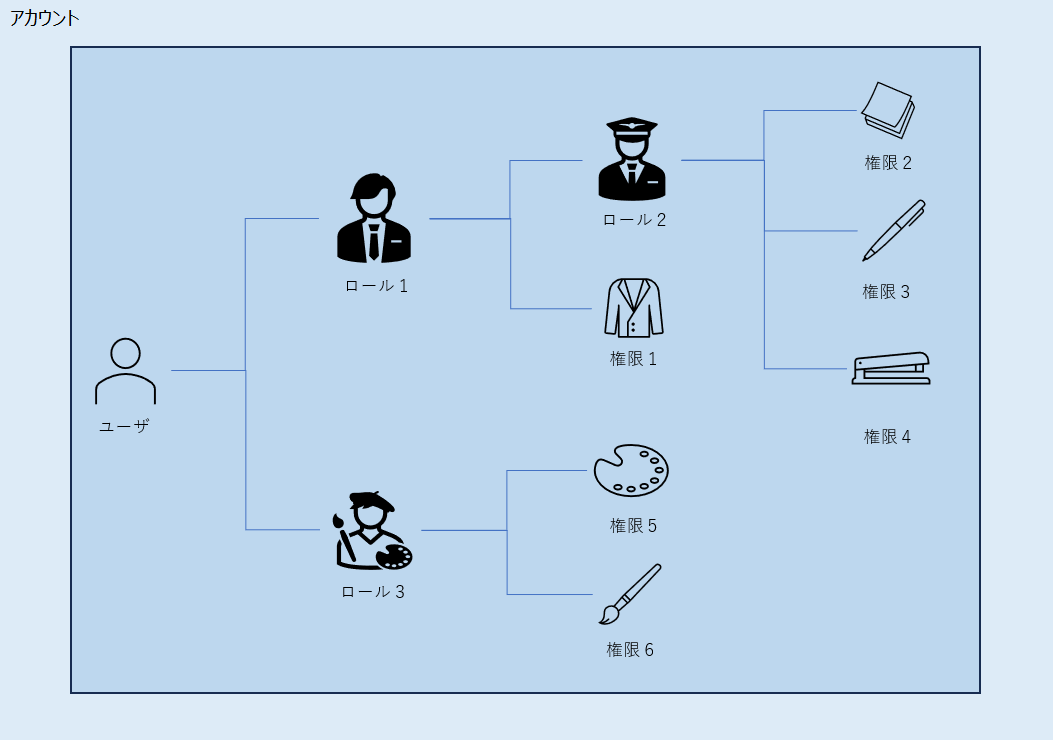
拙い図で恐縮ですが、それぞれの関係は上のようなイメージです。
- アカウントとはSnowflake環境そのものを指します。
- ユーザはその名の通り、アカウントにログインできる人です。
- ロールにはシステム定義のロールとカスタムロールがあります。
権限をまとめたものであり、カスタムロールはユーザ自身で定義します。
ロールを別のロールに紐づけ、親子関係にすることも可能です。 - 権限とは「できること」そのものです。
データベースに対する操作(CREATE/SELECT/UPDATE...etc)や、
ウェアハウスの使用など、多岐にわたり細かくロールに紐づけられます。
これらロールと権限をユーザに割り当てることで、そのユーザができることが決まります。
ロールが職業で権限が持ち物、みたいなイメージですね。
データ閲覧者にどんな権限をつける?
では実際にどんな権限をつけていくかですが、まずデータを閲覧する際の流れを整理します。
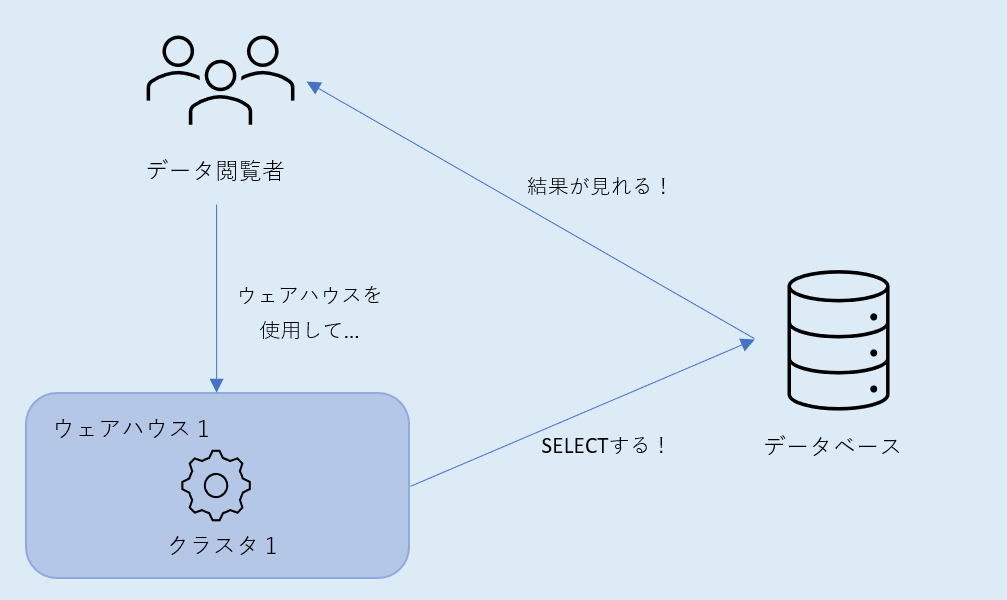
上図の通りです。
ウェアハウスは「クエリ実行時のエンジン的なもの」でした。なので、SELECT文でデータを取ってくるには、エンジンであるウェアハウスを使用できる権限がないとデータベースに命令ができません。また、データベースにアクセス可能で、かつテーブルへのSELECT許可がない状態だと、データを取ってくることはできません…
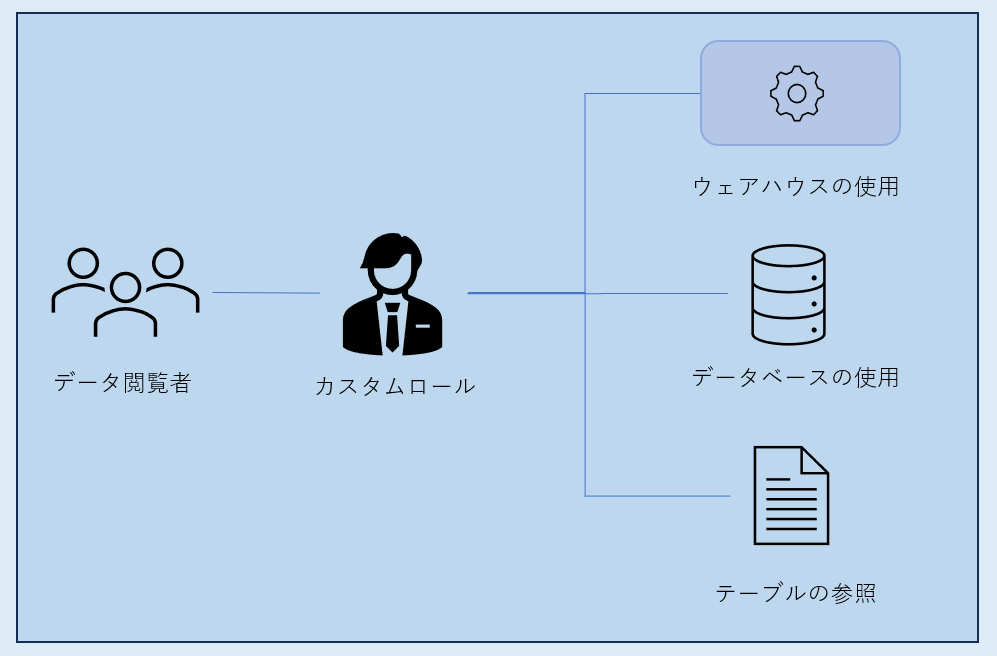
なので、
- ウェアハウスを使用できる権限
- 必要なデータベースにアクセスできる権限
- アクセス可能なデータベース内のテーブルをSELECTできる権限
のみを付与したカスタムロールを作成し、ユーザ作成時に割り当てます。
もし運用時に何か問題があり、テーブルを作り直す等が起きた際には、このカスタムロールを通してデータ閲覧者を一括管理する方針としました。
Snowflakeは細かく権限管理できる分、流れを整理してから権限付与すると漏れがなくて安心です!
保守・運用のための仕込み
運用期間中、連続してデータ提供できることがベストです。
そのため、もし万が一テーブルが壊れた等の場合、迅速に復旧できる方法は押さえておきたいところ。そんな保守・運用面での機能をご紹介します。
クエリ履歴の確認
下記UIからクエリの履歴を確認できます。
システム的なクエリも含まれていますが、ユーザが明示的に発行したクエリには使用したウェアハウスが記載されます。

運用期間中、定期的にウォッチし、処理時間や使用したクラスタ数からウェアハウスの性能を変更する等を行います。
クエリIDによるロールバック
このクエリ履歴の使い方の一つとして、クエリIDを用いてテーブルをロールバックできる点があります。
//UPDATE文のクエリIDを控える
SET query_id =
(SELECT query_id FROM TABLE (information_schema.query_history_by_session (result_limit=>5))
WHERE query_text LIKE 'update%' ORDER BY start_time DESC LIMIT 1);
//テーブル再作成
CREATE OR REPLACE TABLE テーブル名称 AS
(SELECT * FROM テーブル名称 BEFORE (statement=>$query_id))
予めクエリIDを取得し、そのクエリIDが発行される直前の断面にテーブル置換(REPLACE)することで復元可能です。先ほどのUIからクエリIDを取ってきてもいいですし、テーブルのクエリ履歴セッションからSQLで検索することもできます。
(上図はUPDATE文を検索してクエリID取得したものです)
ちなみに、Snowflakeではこうした過去データへのクエリや復元を総称して「Time Travel」と言います。なんかカッコいいですよね~!笑
(参考)Time Travelの理解と使用 | Snowflake Documentation
ストリームによる追跡
運用期間中、万が一にはクエリIDでロールバックしようと思います。
ですが、実際に予期せぬデータ変更があった場合、どう検知するの??という問題があります。そこで活躍するのがストリームというオブジェクトです。
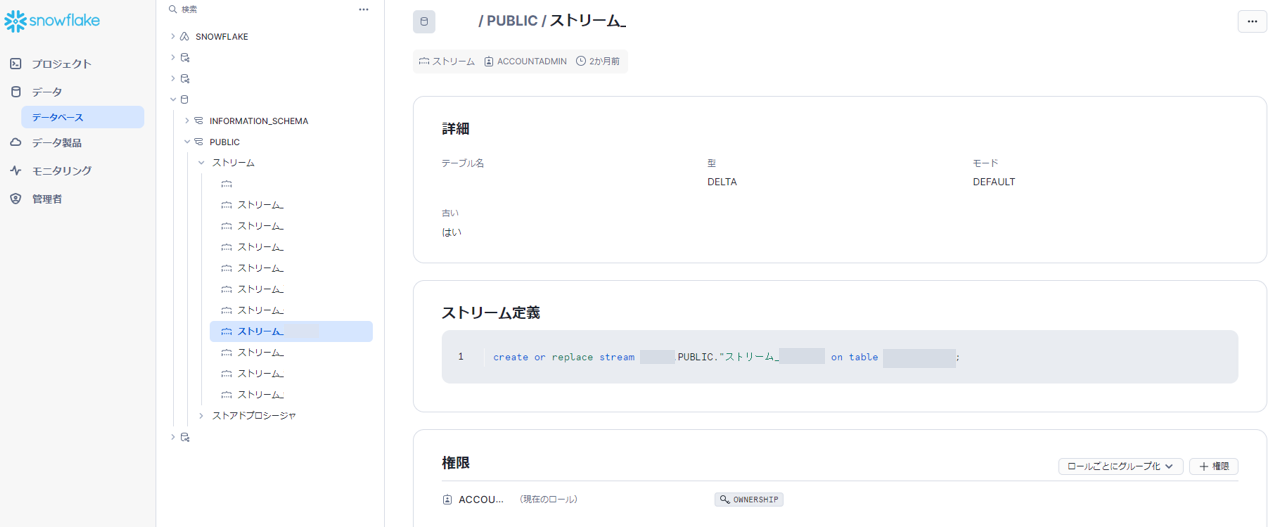
ストリームとは、ストリーム作成時点と比較し更新・削除等によるテーブル変更履歴をため込むことができる、という便利グッズです。
ストリームはテーブル単位で作成し、当該テーブルに対する変更を記録します。そういう特性もあり、あたかもテーブルのようなUIで出ます。
(所々マスクしているので見づらいかもしれません...)
データ提供を開始する前に、提供するテーブルそれぞれを紐づけたストリームを作成することで、保守対応に向けた「仕込み」を行います。
(参考)CREATE STREAM | Snowflake Documentation
SELECT テーブル名称1 AS "テーブル名", COUNT(*) AS "行数" FROM ストリームが属するデータベース.スキーマ.ストリーム名称1
UNION ALL
SELECT テーブル名称2 AS "テーブル名", COUNT(*) AS "行数" FROM ストリームが属するデータベース.スキーマ.ストリーム名称2
UNION ALL
...
実際の運用では、テーブル変更などをすぐに確認できるよう、上のような専用クエリを用意していました。(各ストリームの行数を一気に出力する、というもの)
テーブル変更があれば行数に1以上がつくので一目瞭然です。
これで変更検知できるので、いざという時はクエリIDによるロールバックで対処いたします。
余談ですが、SnowflakeのUIにはダッシュボードという機能もあります。詳細には試していませんが、その名の通りクエリ結果を常に可視化できる一画面のようです。今回は運用面での実施事項が少なかったので個別にクエリ叩いて結果確認しましたが、いろいろウォッチしておきたい、という時は便利なツールに思えました。
やってみてのSnowflakeの印象
これでデータレイク構築が完了しました。今回の経験で良かったと思う点をまとめます。
リーダーアカウントの有用性
Snowflakeはデータ共有が容易であることを様々な記事で拝見しておりましたが、リーダーアカウントはたしかに便利でした。ユースケースとしては顧客企業へのデータ提供など。Snowflakeのアカウントを持っていない先、かつ先方にてデータ変更を必要としない場面で有効と思われます。
良心的な価格設定
Snowflakeはコンピュートとストレージを分離して構成されている点が特徴ですが、特にストレージにかかるお金が安いと思われます。(他と比較していないのであくまで主観ですが…)
その分、TimeTravel機能(=クエリIDによるロールバック等)のためのデータ保持容量も充てられるので、使い勝手がいいな~と思いました。
サポートが早い
あまりご紹介していませんでしたが、サポートへの問い合わせもUIから可能です。実際に何度かやり取りしました。日本語にも対応しており、何よりレスが早かったです!(翌日までには何かしら初動のレスが来ていた印象)
ちなみに、レスは日本語のときと英語のときがあり、私は日本語/レスは英語、といった不思議なやり取りもしていました(笑)
UIでできることが多い
SnowflakeはUIが豊富で使いやすかったです。構築時にもUIでできるところは積極的に活用しておりました。結果、UIとSQLで半々くらいの作業量でした。
日本語にも対応しているので、UIを見てわからない点はほぼありません。勿論、詳細なパラメータ設定に関してはコマンドで対応する必要はありますが、UIが充実しており日本語対応な点は取っ掛かりのハードルがグッと下がります(笑)便利な時代です~
記事の終わりに
ここまでSnowflakeによるデータレイクの構築と体験記を、前編/後編に渡りご紹介させていただきました。
今回はシンプルな構成で使用ユーザも限られた環境でしたので、他にもまだまだSnowflakeの強力な機能があると思いますが、何かしらで本記事がご参考になれば嬉しい限りです。
長い間お付き合いいただきありがとうございました!!
