
概要
三菱総研DCSで新技術のリサーチを担当している諸星です。
アマゾンウェブサービス(AWS)が提供する音声文字起こしサービスAmazon Transcribeが2019年11月に日本語対応したということで、さっそく試してみました。Amazon Transcribeには、人手による文字起こし作業を軽減させ、残業やコストの削減が期待できます。 本記事では、複数人が発言する会議というシチュエーションにおける音声文字起こしサービスの検証結果を紹介します。
そもそもAmazon Transcribeとは
Amazon Transcribeは、ユーザーが用意した音声ファイルをテキストに変換できる自動音声文字起こしサービスです。ヘルプデスクにおける会話内容の文字起こしや、ニュース・映画・ドラマなどの字幕生成への利用が想定できます。また、最近では企業や官公庁における会議の議事録作成においても活用が期待されます。
必要な準備として
今回はiPhoneの音声レコーダーを利用して模擬会議内容を録音します。模擬会議は、営業担当者の鈴木さんとその上司が打ち合わせをしている様子を想定しました。音声データファイルはWAV形式で保存し、会議の長さは約1分30秒程度です。
また、今回の音声データには、従来の音声文字起こしソフトでは誤認識が多かった以下のパターンを盛り込んでみようと思います。
① 感動詞「あのー」、「うーん」、「あっ」、「えっと」を使ってみる
② 声のトーンを変えてみる(急に大きな声を出す)
③ 緊張や焦りによるどもり
④ 二名で声を重ねてみる(重複話者)
⑤ 対話の途中にアラーム音を鳴らせてみる
検証と結果
検証は、以下①~④の流れで行いました。
① 録音した音声データのアップロード
録音した音声データをAWSのS3上へアップロードします。
② ジョブの作成
AWS Transcribe上で、ジョブを作成します。ジョブとは、文字起こし作業の単位です。
(画像は、AWS Transcribeの設定画面の一部です。右上の「Create Job」というボタンを押すとジョブが作成されます。)
 ③ 文字起こしする言語の選択
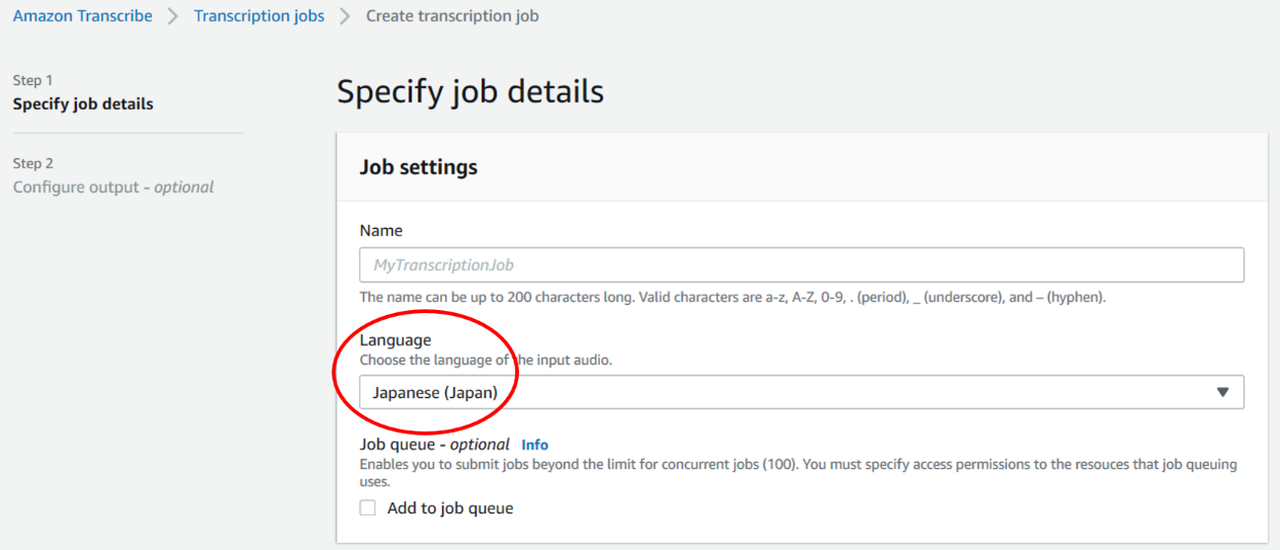
③ 文字起こしする言語の選択
検証用音声データの言語である日本語を選択します。2020年3月3日現在で、計31言語の文字起こしに対応しています。
 ④ オプション機能の選択
④ オプション機能の選択
オプション機能としては下記があり、今回の検証ではこの中の話者識別機能である「Audio identification」をオンにしてみます。
・Audio identification: 話者識別
・Alternative results: 代替結果生成
・Vocabulary filtering: 単語フィルター
・Custom vocabulary: カスタム語彙利用
文字起こしの結果は以下です。
文章毎に正しく認識していたら、“〇”、1文字でも誤認識していたら“×”とします。
------------------------------------------------------------------------------------------------
上司(発話音声):えーっと、先月のアポの数を教えてください
上司(認識結果):えーっと 先月 の アポ の 数 を 教え て ください
評価: 〇
------------------------------------------------------------------------------------------------
鈴木(発話音声):うーん、先月はアポイントが十五件でした
鈴木(認識結果):先月 は ポイント が 十 五 件 でし た
評価: ×
------------------------------------------------------------------------------------------------
上司(発話音声):十五件か、わかりました
上司(認識結果):十 五 件 か 分かり まし た
評価: 〇
------------------------------------------------------------------------------------------------
上司(発話音声):えーっと売り上げを教えてください
上司(認識結果):えーっと 売り上げ を 教え て ください
評価: 〇
------------------------------------------------------------------------------------------------
鈴木(発話音声):えーっと、売り上げは三千万くらいです
鈴木(認識結果):えっ と 売り上げ が 三 千 万 くらい です
評価: ×
------------------------------------------------------------------------------------------------
上司(発話音声):三千万か、うーん、困っちゃったね
上司(認識結果):三 千 万 か 困っ ちゃっ たね
評価: 〇
------------------------------------------------------------------------------------------------
上司(発話音声):勝率はどのくらいでした?
上司(認識結果):勝率 は どの くらい でし た
評価: 〇
------------------------------------------------------------------------------------------------
鈴木(発話音声):勝率は悪くなかったです
鈴木(認識結果):勝率 は 悪く なかっ た です
評価: 〇
------------------------------------------------------------------------------------------------
鈴木(発話音声):訪問先の九割は受注を貰いました
鈴木(認識結果):訪問 先 の 九 割 は 樹脂 を 貰い まし た
評価: ×
------------------------------------------------------------------------------------------------
上司(発話音声):あっ、ソレは良かったですね
上司(認識結果):あ ソレ は 良かっ た です ね
評価: 〇
------------------------------------------------------------------------------------------------
上司(発話音声):えーっと、じゃあ、今月の予定を教えてください
上司(認識結果):えーっと じゃあ 今月 の 予定 を 教え て ください
評価: 〇
------------------------------------------------------------------------------------------------
鈴木(発話音声):あのー、今月は大阪と京都へ出張へ行きます
鈴木(認識結果):あのー 今月 は 大阪 と 京都 へ 出張 へ 行き ます
評価: 〇
------------------------------------------------------------------------------------------------
上司(発話音声):大阪と京都。そうですか
上司(認識結果):大阪 と 京都 そう です か
評価: 〇
------------------------------------------------------------------------------------------------
上司(発話音声):えーっと、見込み顧客はいますか
上司(認識結果):えーっと 見込み 客 が あり ます か
評価: ×
------------------------------------------------------------------------------------------------
鈴木(発話音声):えー、いません
鈴木(認識結果):い? ませ ええ
評価: ×
------------------------------------------------------------------------------------------------
上司(発話音声):えっ!(急に大きな声を出す)いないんですか、いないのに、出張に行ってどうすんですか?
上司(認識結果):い ない です か い? ない のに 出張 行っ て どう する
鈴木(認識結果):ん です か
評価: ×
------------------------------------------------------------------------------------------------
鈴木(発話音声):(こ、こ、こ、これから)、ア、ア、アア、ポ先を見つけます
鈴木(認識結果):ここと ここ これから 後先を 見つけ ます
評価: ×
------------------------------------------------------------------------------------------------
*上司(発話音声):うーん、大丈夫それで
上司(認識結果):うん
評価: ×
------------------------------------------------------------------------------------------------
*鈴木(発話音声):大丈夫です。大丈夫っすよ
鈴木(認識結果):大丈夫 だ 大丈夫 です よ
評価: ×
------------------------------------------------------------------------------------------------
上司(発話音声):大丈夫?
上司(認識結果):大丈夫
評価: 〇
------------------------------------------------------------------------------------------------
上司(発話音声):そうか、君が言うのなら心配ないでしょう
上司(認識結果):そう か 君 が 言う の なら 心配 ない でしょ
評価: ×
------------------------------------------------------------------------------------------------
上司(発話音声):今月もよろしくお願いします
上司(認識結果):今月 も よろしく お願い し ます
評価: 〇
------------------------------------------------------------------------------------------------
鈴木(発話音声):はい、オンプレの既存顧客を中心に、アポ開拓します
鈴木(認識結果):はい ポンパレ の 顧客 を 中心 に アップ開拓 し ます
評価: ×
------------------------------------------------------------------------------------------------
上司(発話音声):分かりました
上司(認識結果):分かり まし た
評価: 〇
------------------------------------------------------------------------------------------------
上司(発話音声):よろしく頼みますよ
上司(認識結果):よろしく 頼み ます よ
評価: 〇
------------------------------------------------------------------------------------------------
上司(発話音声):為念(ためねん)だけど、来週の会議の司会は、鈴木さんなので、忘れずにお願いしますよ
上司(認識結果):ため ん だ けど 来週 の 会議 の 司会 は 鈴木 さん な ので 忘れ ず に お 願い し ます よ
評価: ×
------------------------------------------------------------------------------------------------
鈴木(発話音声):了解でーす
鈴木(認識結果):ヨガ や です
評価: ×
------------------------------------------------------------------------------------------------
*二人の声が重なる
認識精度は全体的に想定よりも高いように思われました。文章数計“27個”のうち、〇の数は“14個”であり、半分以上の文章に関して修正がほとんど必要ないです。残りの”13個”の文章に関しては、若干の修正の必要性が見受けられるものの、従来の人手による音声データの文字起こしに費やされる時間と比較すると、修正にかかる時間は微々たるものです。
音声データから発話者を識別する話者識別機能に関しては、今回は2名での検証ですが、概ね話者の識別が正確にできました。機能上は最大10名まで識別ができるようです。
誤認識に関しては、単語の一部分が欠ける場合があり、「アポイント」が「ポイント」に、「顧客」が「客」に誤って認識されてしまいました。しかし、元単語から著しく違うということは多くなかったので精度は悪くないです。
業界の専門用語は誤認識される場合がありました。IT業界の専門用語である「オンプレ」は「ポンパレ」と誤認識されました。また、一部の企業において用いられ、一般的にはあまり用いられないとみられる「為念」は「ためん」となり、正確な認識はされませんでした。
従来の音声文字起こしソフトでは誤認識が多かった事項に関しては、以下のような結果です。
① 感動詞「あのー」、「うーん」、「あっ」、「えっと」の認識結果
感動詞に関しては概ね認識してしまいました。しかし、今回使われた4つの感動詞のうち、「うーん」に関しては認識すらされませんでした。議事録の文字起こし作業では、こうした感動詞を「言いよどみ」として除去しますので、感動詞を認識しないことは議事録作成においては便利な場合もありえます。しかし、感動詞ではなく指示語の「あの」のように、消されるべきではないケースもあるので、認識されないことが良いとは一概にはいえないと思います。
| 感動詞 | あのー | うーん | あっ | えっと |
| 認識結果 | × | ○ | × | × |
② 声のトーンを変えてみた際の認識結果
急に出した大きな声「いないんですか」が「い ない です か い?」と認識されました。急に大きな声を出した際にも概ね正しく認識はできるようですが、少なからず認識結果に影響が及ばされる事は考えられます。
③ 緊張や焦りによるどもりの認識結果
「ア、ア、アア、ポ先」が「後先」と認識されました。緊張や焦りによるどもりの認識には弱いようです。
④ 声を重ねてみた際の認識結果
上司と鈴木さんで「大丈夫」が被さるタイミングで合計三回発言されているはずですが、鈴木さんの声のみ認識されます。鈴木さんの声は大きかったので認識され、声が小さかった上司の声はかき消されたようです。
上記の検証に加え、会話の途中でもしノイズが入った場合はどうなるのかも試してみました。
⑤ 対話の途中にアラーム音を鳴らせてみた際の認識結果
別の検証用音声データを準備し、以下の対話中にアラーム音を鳴らせました。
その結果、「困っちゃったね」が「止まっちゃったね」と認識されました。バックグラウンドのノイズによって認識精度が下がったようです。
------------------------------------------------------------------------------------------------
上司(発話音声):三千万か、うーん、困っちゃったね。えーっと勝率はどのくらいでした?
上司(認識結果):三千万か うん 止まっちゃったね えーっと勝率はどのくらいでした
------------------------------------------------------------------------------------------------
まとめ
Amazon Transcribeが日本語対応したということで今回試してみました。検証の結果、想定以上に認識精度が高いことにたいへん驚きました。誤認識された箇所の修正が少々必要でしたが、検証結果を見る限り、それ相当に正しい会話を推測することができました。エンジニアのように特別なスキルがなくても、音声データのアップロードから文字起こしまでを数分で行うことができ、使い方は簡単です。文字起こしにかかる時間も、1分30秒程度の音声データの場合、30秒程度でできてしまいました。従来の人手による音声データの文字起こしに費やされる時間を考えると、文字起こし作業時間の大幅な短縮になると思われます。ビジネスでの活用においても、若干の修正に関しては気をつける必要はありますが、十分利用が考えられると思います。Amazon Transcribeは、企業における働き方改革に向けたツールとしても期待できるのではないでしょうか。
用語解説(付録)
オンプレ
オンプレとは、「オンプレミス」の略です。オンプレミスは、サーバーやネットワーク機器などの購入をし、自社の建物の中に設置する システムのことを言います。
為念(ためねん)
為念とは、一部の企業において用いられる用語であり、「念のため」の意味です。
