
概要
三菱総研DCSデジタル企画推進部の村田です。
前回はプロセスマイニングについて、以下の記事を紹介しました。
Apromore(アプロモーレ)を使ったはじめてのプロセスマイニング
今回はプロセスマイニングにおけるログの前処理について投稿したいと思います。
いざ、業務ログをプロセスマイニングツールにアップロードしようとしても、タイムスタンプのフォーマット変換や名寄せなどのログの前処理が必要となってきます。
ログの前処理はデータが少ないときは手作業でも問題ないのですが、多くなる場合は非常に大変ですよね?
そこで今回は、コーディングなし、GUI操作のみで、プロセスマイニングのための面倒な前処理プロセスを効率化できる「Alteryx」の使い方をステップバイステップでご紹介します。Alteryxは簡単にインストールでき、おススメです。
前提
使用する業務ログデータは単一ログで、CSVファイル形式という前提で説明します。
プロセスマイニングにおけるログの前処理と課題とは
プロセスマイニングでは以下の項目が必要となります。
・必須項目:Case ID、Activity、Timestamp
・属性項目:役職、ロール、チーム名、経験年数、単価など詳細な分析をする上で必要な項目
上記項目に対して、ログの前処理を実施後、最終的に一つのCSVファイルをアウトプットとして出力します。
それでは具体的にログの前処理で実施する内容を見ていきたいと思います。
プロセスマイニングにおけるログの前処理
必須項目であるCase ID、Activity、Timestampと詳細な分析をする上で必要な属性項目(役職、ロール、チーム名、経験年数、単価など)に対して以下の前処理を実施します。
| 項目 | 概要 |
|
不要列削除
|
プロセスマイニングで使用しない列を削除
|
|
日付型変換
|
Timestampのフォーマット変換(yyyy-MM-dd HH:mm:ss)
|
|
名寄せ
|
Activity、属性項目の内容を名寄せする
|
|
置換
|
Activity、属性項目の内容を置換する
|
|
ノイズ除去
|
Null、文字化け、空白、欠損値を除去する
|
|
関連付け
|
関連のある複数ログを統合するためにプロセスIDを割り当てる(Case ID)
|
|
データ抽出
|
期間等の指定、プロセスのスタート、エンドを指定、分割等
|
上記の前処理をPythonなどでコーディングすると以下の課題が挙げられます。
課題
① Pythonでは複雑な処理をコーディングするため、コードのメンテナンス性が損なわれやすい(設計書もいちいち書いていられない)
② 業務プロセスを改善するサイクルに組み込むには、コードを定期実行する仕掛けが必要
③ 試行錯誤を重ねていく中で、ログの追加/削除が頻繁に起こり、コーディング内容の変更が発生して負荷が高い
上記の課題をAlteryx製品の一つであるAlteryx Designerの14日間のトライアルを使って解消できるか実際の業務ログを用いて検証してみたいと思います。
Alteryx Designerとは
概要
Alteryx Designerとはデータの入力、選択、加工、集計、多変量解析などを、複雑なプログラムコードを書くことなく、マウス操作だけで実現できるツールです。
使い方
Alteryx Designerの使い方は、各機能アイコンをドラッグ&ドロップでキャンバスに配置することで、ワークフローを作成していきます。デフォルトで200以上ものアイコンが用意されています。
実際に使ってみたところ、プロセスマイニングのほとんどのログの前処理を実施することができました。
以下はワークフロー作成の実施手順です。
まず、「データ入力ツール」でファイルを読み、次に、「閲覧ツール」で全量データの中身を確認しています。
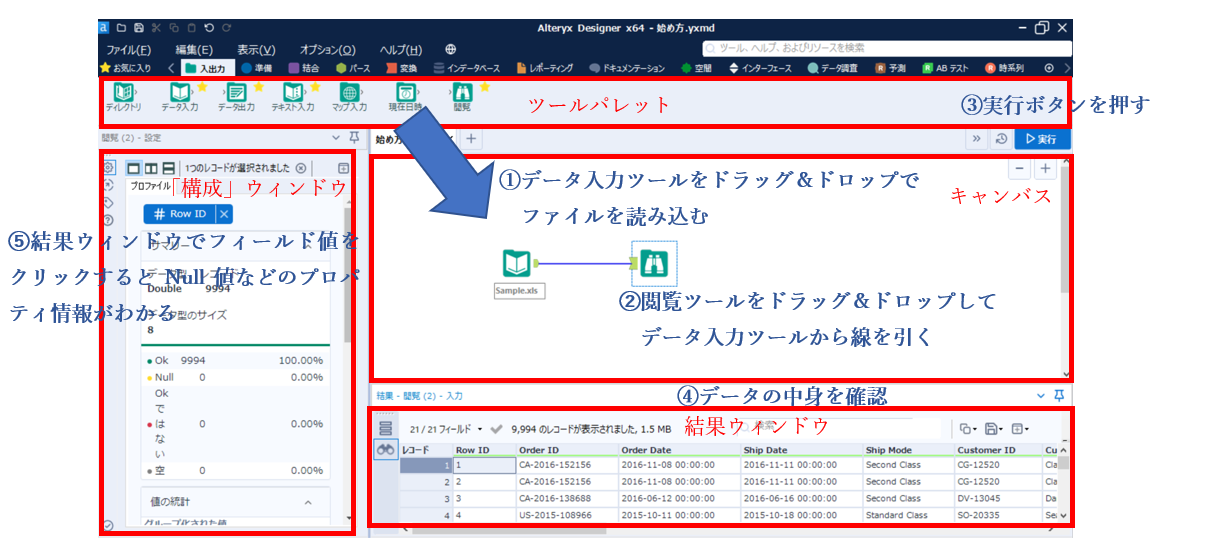
検証してみる
Alteryx Designerは14日間の無料トライアルができます。
トライアルの準備
以下のURLにアクセスし、アカウント登録をしてください。
無料トライアル
登録するとexeファイルがダウンロードされるので、ダブルクリックしてPCにインストールします。インストールは画面の案内に従ってボタンをクリックするだけで簡単にできます。
今回は以下の環境にインストールします。
・OS:Windows 10 64bit
検証
・今回前処理を試してみる業務ログデータ
ワークフローログ(2019年1月1日~2019年9月30日分)
内容:一般の企業でよくある申請と承認のフローです。
・Case ID、Activity、Timestamp、属性項目に対して前処理を実施
(データ整形前)

日付型や表記ゆれなどを整形し、プロセスマイニングツールにアップロードができるように処理します。
(データ整形後)

データ整形後の状態にするために以下を実施します。
・プロセスマイニングで使用しない列を削除
・Case IDフィールドの設定
・Timestampのフォーマットを変換(yyyy-MM-dd HH:mm:ss)
・Activityフィールドの設定(Null値がある項目は隣の列から値を設定して整合性のあるものにします。)
・特定期間のログを分析したい場合は、期間を2019年4月1日以降のように指定
前処理フローの作成
作成する前処理フローは以下となります。作成手順について順を追って説明していきます。
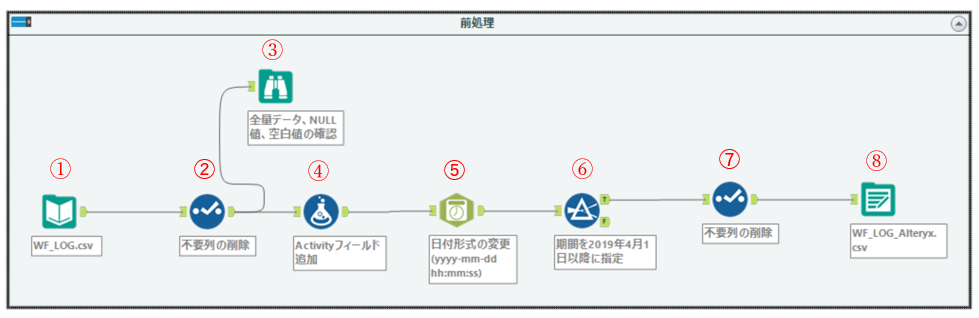
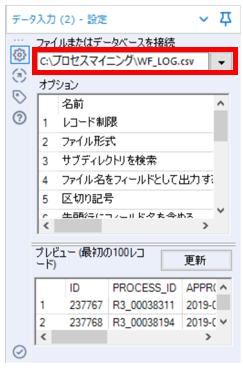
①「テキスト入力ツール」で読み込むファイルを指定します。
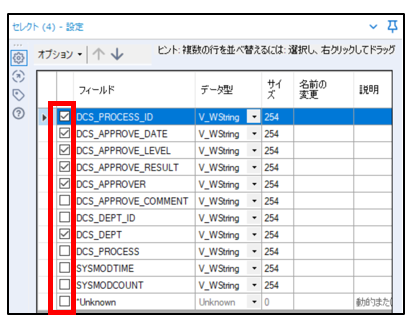
➁「セレクトツール」で必要なフィールドのみ残し、不要なフィールドはチェックを外します。
③プロセスマイニングでは、プロセスIDが必須となりますので、プロセスIDフィールドにNull値や空白値がないことを確認します。
「閲覧ツール」では、データ全量における各フィールド内のNull値、空白値が確認できます。
以下ではDCS_PROCESS_IDフィールドのNull値と空白値は0件であることがわかります。

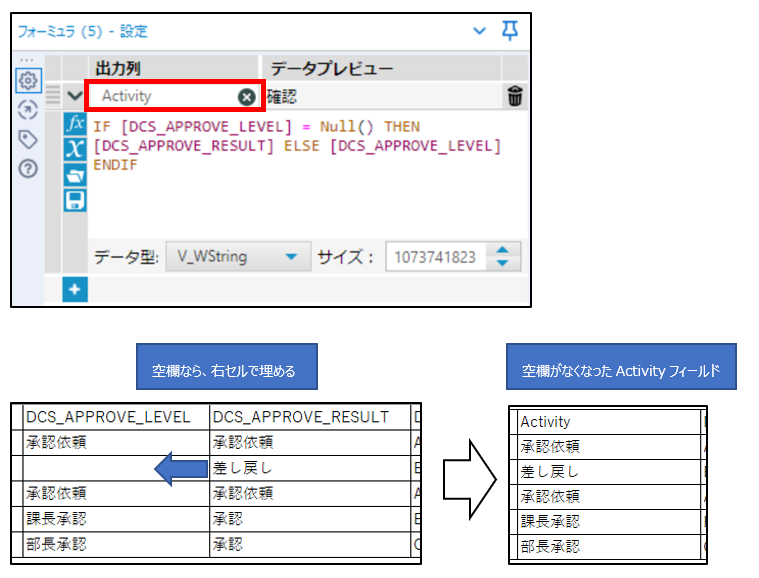
④「フォーミュラツール」でActivityフィールドを追加します。
出力列にActivityと入力するとActivityフィールドを追加できます。
Activityの項目がNullの場合があるので、IF文を使って内容を設定しています。
IF文は一から書く必要なく、クリック操作で雛形が作成できます。
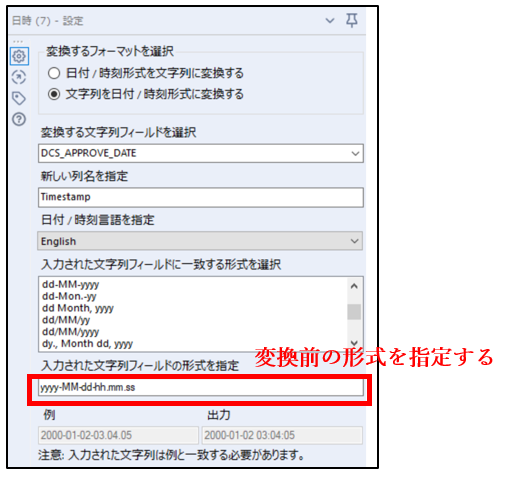
➄「日時ツール」でDCS_APPROVE_DATEフィールドの日時形式を以下のように変換します。変換後は新しくTimestampフィールドを追加します。どの形式に変換するかは、お使いのプロセスマイニングツールによります。
(変換前)yyyy-MM-dd-hh.mm.ss → (変換後)yyyy-MM-dd HH:mm:ss
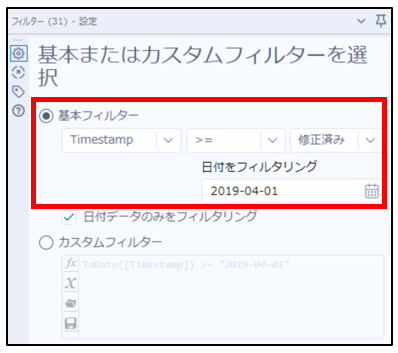
⑥「フィルターツール」で期間を2019年4月1日以降に指定して、条件にマッチするデータを出力します。
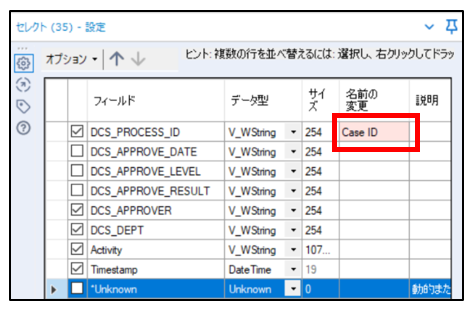
➆これまでの前処理作業で不要なフィールドが生成されている場合がありますので、「セレクトツール」で再度、必要なフィールドのみを残し、不要なフィールドを削除します。
また、最終的なフィールド名の変更も、この画面で行います。
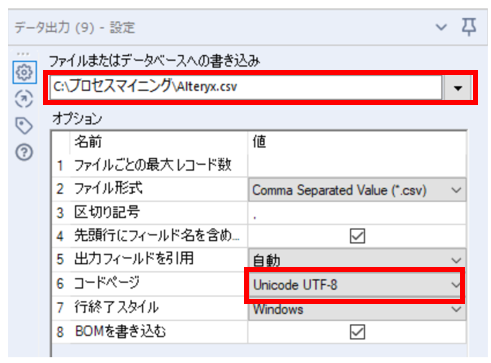
⑧「データ出力ツール」でファイルを指定のディレクトリに出力します。
文字コードをUTF-8に指定します。(文字化けが発生しないように)
課題に対する結果
最後にAlteryx Designerを用いて課題が解消されたかを考察していきたいと思います。
結果
課題① Pythonでは複雑な処理をコーディングするため、コードのメンテナンス性が損なわれやすい(設計書もいちいち書いていられない)
→ 複雑な処理をコーディングすることなく、Alteryx Designerが提供しているツールのみで今回の前処理を実施できた。また、作成したワークフロー自体が設計書として活用でき、メンテナンス性を維持できる。
課題② 業務プロセスを改善するサイクルに組み込むには、コードを定期実行する仕掛けが必要
→ 一度、ワークフローを作成してしまえば、同じ処理を何度でも実行可能となる。
課題③ 試行錯誤を重ねていく中で、ログの追加/削除が頻繁に起こり、コーディング内容の変更が発生して負荷が高い
→ 今回は単一ログのみ扱ったため、検証できず。次回複数ログを組み合わせて検証実施予定。
まとめ
今回の検証では単一ログのみの検証でしたが、ログの前処理を効率的に実施することができました。複雑な処理をコーディングすることなく、Alteryx Designerが提供しているツールでログの前処理を実施可能なので、エンジニア以外の方でも簡単に実施できるので非常におススメです。
次回は複数ログを組み合わせた前処理の検証を実施していきたいと思います。
