
はじめに
AI開発やデータ分析業務を行っている平井です。
今回は、Apache Sparkでの開発効率を向上させるAsakusa Frameworkについて、実際に簡単なバリデーションチェックを実装して使ってみたので 開発の仕方や使用感についてご紹介します。
目次
概要
バッチ処理を構築する際、ピーク時のコンピューティングリソースを準備する必要があり、等比級数的に増加する処理量に応じて、リソースを増加させるのは、コスト的面でも負荷面でも大変となります。 そのような場合にApache Sparkで分散処理を行いたいけれど、pySparkやSparkJavaは、独自の作法があり学習するのも一苦労必要です。そこで、Javaのまま使えるAsakusa Frameworkをやってみました。 今回、開発をWindows10上のeclipseで行い、どのように開発していくかを試してみました。 簡単なバリデーションチェックの実装を通してAsakusa Frameworkの実行方法や使い勝手などをお伝えいたします。
前提
今回の開発は以下の前提で開発しています。
| 開発環境 | |
| OS | Windows10 |
| IDE | Eclipse |
| 言語 | Java SE8 + Asakusa Framework(0.10.3) |
Asakusa Frameworkとは
基幹業務システムバッチをHadoopやSparkを用いて分散処理を行う際、分散処理の作法を意識せずにより簡単に記載することを主目的として作られたフレームワークです。 データ量が多くデータフローやデータ処理方式があらかじめ決まっているバッチアプリケーションなどをJava Sparkコードへ変換する機能が備わっていることが特徴です。開発言語はJava SEのため、Javaを開発したことがある方なら比較的敷居が低いです。 Asakusa Frameworkでは、Asakusa DSLという方式に沿って記載する形となります。この処理方式に関しては実装の章で詳しく記載します。 記載したコードはgradleファイルでコンパイルすることができます。Asakusa Frameworkでは、gradleファイルの記載を変えるだけで、ローカルコンピュータ用の実行ファイル(vanilla)や、Spark環境用の実行ファイル、また単一マルチコアサーバでの実行ファイル(M^3)など複数の実行基盤に対応したコンパイルが出来るのも特徴の一つです。 開発環境はeclipseのpluginから導入することができ、簡単に導入することができます。
実装
今回の実際のバリデーション処理を実装していきます。 EclipseにAsakusa Frameworkを導入する方法については、Asakusa公式HP(https://docs.asakusafw.com/jinrikisha/ja/html/shafu.html)をご参照ください。 今回は、入力用のCSVファイルを用意しておき、そのCSVファイルの各レコードに対して簡単なバリデーションチェックを行って結果をCSV出力するという流れで実装していきます。入力CSVは氏名がそれぞれ姓と名に分かれてカラムが作られているものを想定し、姓カラムがnullだった場合、エラーを出力するという流れにしています。
データの準備
Asakusa Frameworkで作成したSparkプログラムでの基本的なデータの入出力は、HadoopのHDFS上に配置したCSVファイルかHiveで作成したORCファイルとなります。今回は、Windows上で実行するためデータの処理対象のファイルは、Windows上の指定のディレクトリに保存しています。
DMDLファイルの作成
Asakusa Frameworkのデータモデル定義はDMDLという独自のファイルに記載します。このファイルは入出力するデータの型を定義しているため今回使用するデータ定義分作成する必要があります。DMDLファイルは、処理するテーブルやCSVファイルの単位ごとに作成する必要があります。このファイルを作成しプロジェクトをコンパイルすると自動でJavaのデータモデルクラスが作成されます。
- sample.dmdl
"入力サンプルファイル"
@directio.csv(
charset = "SJIS",
date = "yyyyMMdd",
has_header = TRUE
)
sample = {
"氏名・姓"
@directio.csv.field(name = "sei")
sei : TEXT;
"氏名・名"
@directio.csv.field(name = "mei")
mei : TEXT;
};
ロジックの作成
ここで処理のロジックを書くのですが、その前にAsakusa Frameworkの処理フローを考える必要があります。Asakusa Frameworkは、Batch DSL、Flow DSL、Operater DSLの3つから主に成り立っています。
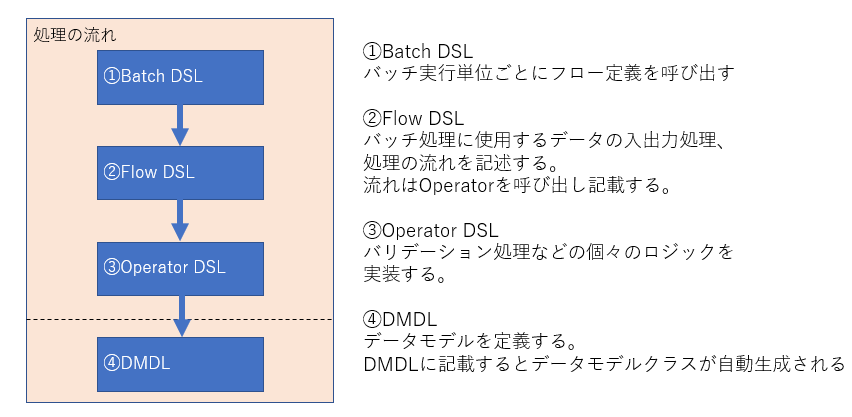
Batch DSL
Batch DSLはバッチの単位ごとに記載します。 今回のコードは以下のようになります。
- sample_batch.java
package com.example.batch;
import com.asakusafw.vocabulary.batch.Batch;
import com.asakusafw.vocabulary.batch.BatchDescription;
import com.example.jobflow.SampleJob;
@Batch(name = "example.Sample")
public class SampleBatch extends BatchDescription {
@Override
protected void describe() {
run(SampleJob.class).soon(); //←バッチ実行クラスの呼び出し
}
}
Flow DSL
Flow DSLは、データの入出力と処理ロジックの流れを記載します。先ほどDMDLファイルから作成した、データモデルクラスの呼び出し等もここで行います。
- sampleJob.java
@JobFlow(name = "SampleJob")
public class SampleJob extends FlowDescription {
final In input; //←入力データ
final Out output; //←正常データ出力用
final Out output2; //←異常データ出力用
public SampleJob(
@Import(name = "Sample", description = SampleFromCsv.class) In input,
@Export(name = "output", description = SampleToCsv.class) Out output,
@Export(name = "output2", description = SampleToCsvForError.class) Out output2) {
this.input = input;
this.output = output;
this.output2 = output2;
}
@Override
protected void describe() {
CoreOperatorFactory core = new CoreOperatorFactory();
SampleOperatorFactory operator = new SampleOperatorFactory();
// 個別のバリデーションチェック(簡略化しています)
ValidateInputData validateInputData = operator.validateInputData(input);
ErrorMessage errorMessage = operator.errorMessage(validateInputData.error);
output2.add(core.restructure(errorMessage.out, Sample.class));
//これ以降にもバリデーション処理を追加できます。
AppendMessage appendedMessage = operator.appendMessage(validateInputData.normal);
output.add(core.restructure(appendedMessage.out, Sample.class));
}
}
Operator DSL
処理ロジックの中身は、次に説明するOperator DSLに記載します。 Operator DSLは、実際のバリデーション処理のロジックを記載します。ここで気をつけなければならないのは、Operator DSLに渡される処理対象データは、CSVファイル全量ではなく、レコード単位で渡されると言うことです。また、記載するロジックのメソッドは、1つアノテーションをつける必要があります。今回は、入力されたレコードに対して、チェック処理がOKかNGかの2択に分ける処理のため、「@Branch」アノテーションで処理を分岐させ、「@update」アノテーションで値を変更して最終的にエラーレコードと正常レコードで書き出しをします。 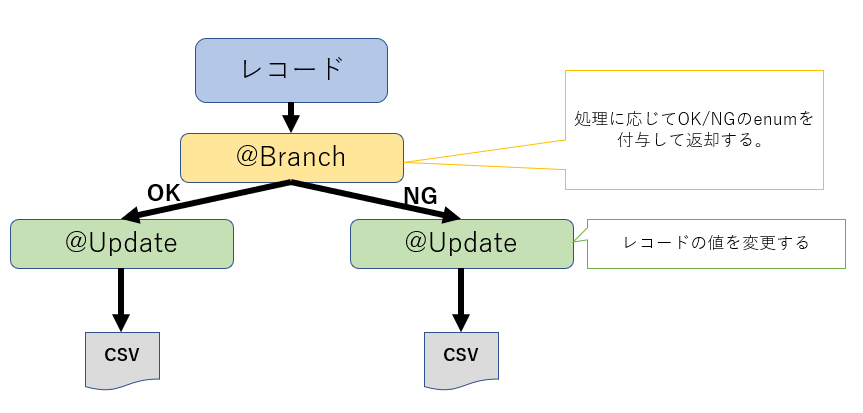
- sampleOperator.java
@Branch //←正常レコードと異常レコードを選り分けるアノテーション
public Status validateInputData(Sample input) {
// 個別のバリデーションチェック
// 氏名・姓
if (input.getSeiOption().isNull()) {
errorList.add("氏名・姓null");
}
continue;
・
・
・
}
if (errorList.size() == 0)
return Status.NORMAL; //←正常/異常のEnumを返却
else
{
for (String msg : errorList) {
Log.info(msg);
}
return Status.ERROR; //←正常/異常のEnumを返却
}
}
デプロイ
今回、作成したコードを実行形式コンパイルするためのbuild.gradleを設定します。 今回はローカルコンピュータ上で実行するので、vanillaの形式でコンパイルする用、build.gradleに記載します。 Spark環境版にコンパイルする場合は、Vanillaの行をコメントアウトしてSparkの行を追加します。
- build.gradle
apply plugin: 'java-library'
dependencies {
implementation 'org.apache.commons:commons-lang3:3.7'
}
apply plugin: 'asakusafw-sdk'
apply plugin: 'asakusafw-organizer'
apply plugin: 'asakusafw-vanilla' //←vanilla pluginを設定
//apply plugin: 'asakusafw-spark' //←Spark pluginをコメントアウト
apply plugin: 'eclipse'
asakusafwOrganizer {
vanilla.enabled true //←vanillaを設定
profiles.prod {
hadoop.embed true
}
//ここに外部ライブラリを記載
extension {
libraries += ["org.apache.commons:commons-lang3:3.7"]
}
}
上記のように設定したらeclipse上で以下のようにコマンドを実行します。
「プロジェクトを右クリック」-「Jinrikisha(人力車)」-「Asakusaデプロイメントアーカイブを生成」を実行
出来上がったtar.gzファイルを事前に設定しておいたAsakusa実行用のディレクトリにおきます。 以下のディレクトリに配置する際、tar.gzは解凍して保存しておきます。
(Windows)
%userprofile%/
└target
└testing/
└ directio/
├ input ←読み込みファイル格納先
| └ sample.csv ←読み込み対象ファイル
├ error ←異常レコード出力先
├ output ←正常レコード出力先
├ _directio_temp ←一時保存ディレクトリ
実行
ファイルの格納が完了したら、コマンドプロンプト上で実行コマンドを打ちます。 事前に以下のようにASAKUSAコマンドを環境変数に追加しておきます。
(環境変数登録)
ASAKUSA_HOME=C:\opt\asakusa
PATH=C:\opt\asakusa\bin ,C:\opt\Gradle\gradle-4.7\bin\
(ASAKUSA実行コマンド)
cd %ASAKUSA_HOME%
java -jar tools\bin\setup.jar
asakusa run vanilla.example.Sample
処理が完了すると、outputディレクトリに正常処理されたレコードが記載されたファイル、errorディレクトリにバリデーションチェックに引っかかったっレコードが記載されたファイルが出力されます。
(Windows)
%userprofile%/
└target
└testing/
└ directio/
├ input ←読み込みファイル格納先
├ error ←異常レコード出力先
├ output ←正常レコード出力先
| └ outputSample.csv ←結果が出力される
├ _directio_temp ←一時保存ディレクトリ
今回は、きちんと正常ディレクトリに出力させることができました。
Asakusa Frameworkをつかってみて
今回、Asakusa Frameworkを使ってみて、私なりによかったと思う点と使いにくいかなと思う点を挙げてみました。
<よかった点>
- Map reduceやSparkに比べ分散処理を意識せずにコードを書くことができた点
- Map reduceだと、どのように分散させて処理させるか等を意識して記載する必要があるが、Asakusa Frameworkはそこを意識せずコーディングが可能でした。
- ロジックを記載する際のアノテーションが豊富でなので、データの処理方式がきちんと定まっているプロジェクトには適応しやすい点
- 書き方が決まっているため、Sparkで一から開発するより開発工数の削減が期待できる。
- Eclipseにpluginを入れることで環境を構築でき、導入が簡単な点
- Javaでコーディングが可能な点
- dmdlファイルはもとにするテーブル生成SQLクエリなどがあれば簡単なコードで変換処理を書くことが可能な点
<Asakusaとして使いにくいと思う点>
- 実行形式がtar.gzに固まってしまうため、実行時に一度解凍しないといけない点
- Operatorクラスのロジックが複雑になればなるほど肥大化してしまい可読性が低くなってしまう恐れがある点
- dmdlファイルを一から作成するのが結構大変な点
- 基にするテーブル作成SQLクエリなどがあれば、簡単なマクロで自動生成することが可能。
<分散処理自体の使いにくい点>
- デバック実行が実行後のスタックトレースを追うしかなく使いにくい点
- レコード単位のロジック記載に慣れが必要な点
- ファイルから読み込んだデータの型がHadoopに寄っており、Java標準のString型等とは違うため比較する際に変換が必要な点
即時のデバック実行ができない点については、SparkとAsakusaどちらにも言えるため、何かしら見えるツールがあれば、より開発がし易いのではないかなと感じました。
まとめ
Asakusa Frameworkを使って簡単なバリデーション処理を実装することができました。 今回は、Asakusa Frameworkをメインに置いたため、Sparkでの実行方法などには触れませんでしたが、build.gradleをSpark用に変更してビルドを行うことで、Spark基盤上でも実行することができるようになります。 Asakusa Frameworkは、一般の記事としては少ないですが、公式のドキュメントが充実しているというのが印象的でした。 今後は、Asakusa Frameworkのもう一つのコンパイル方法であるM^3やHiveを使ったデータの読み出しにも挑戦したいと思います。
関連記事 参考資料
- Asakusa Framework公式
https://docs.asakusafw.com/latest/release/ja/html/index.html - チュートリアル(Linuxサーバ実行)
https://docs.asakusafw.com/basic-tutorial/latest/release/ja/html/deploy-on-spark.html - Shafu(ビルドツール)インストール
https://docs.asakusafw.com/jinrikisha/ja/html/shafu.html
