
概要
三菱総研DCSのIoT・AIエンジニアの日野です。
Keras(Python)上で作成したディープラーニングモデルをWebブラウザ上でも動かしてみたくなり、以前から気になっていたTensorFlow.jsを触ってみました。本記事では、KerasからTensorFlow.jsで使えるモデルに変換する際に苦労したポイントをまとめます。
Keras:TensorFlowまたはCNTK,Theano上で実行可能な高水準のニューラルネットワークライブラリ
(出典元:Keras公式ドキュメント)
TensorFlow.jsとは
TensorFlow.jsとは、2018年4月にGoogleによって公開された、Webブラウザ上でディープラーニングモデルの構築や学習、学習済みモデルの実行が可能になるJavaScriptライブラリです。オリジナル版のTensorFlow(Python)と比較すると速度低下はあるようですが、WebGLを通じてGPUを利用した処理の高速化にも対応しています。
JavaScriptでディープラーニングモデルを扱うためのライブラリとしては、他にもbrain.jsやConvNet.js、Keras.jsがあります。
モデル学習時にはKerasを使用していたため、もともとKeras.jsを使うつもりでしたが、ライブラリの更新が止まっておりドキュメント上でもTensorFlow.jsの使用を推奨していたため、今回はTensorFlow.jsを使用しました。
使用モデルについて
変換するのはWebカメラを使って簡易的に作業者の視線を推論するモデルです。顔の特徴量と目領域の画像を使って注視しているモニター上の座標を推論しています。
動作と処理のイメージは以下の通りです。
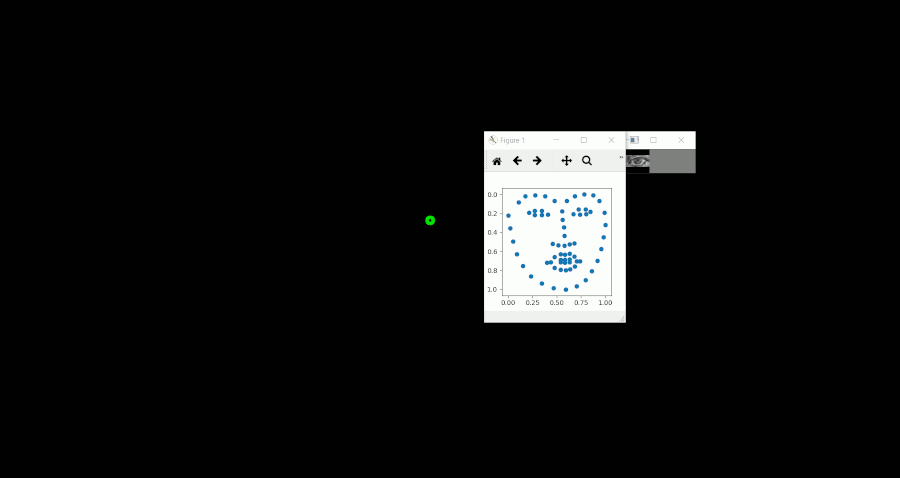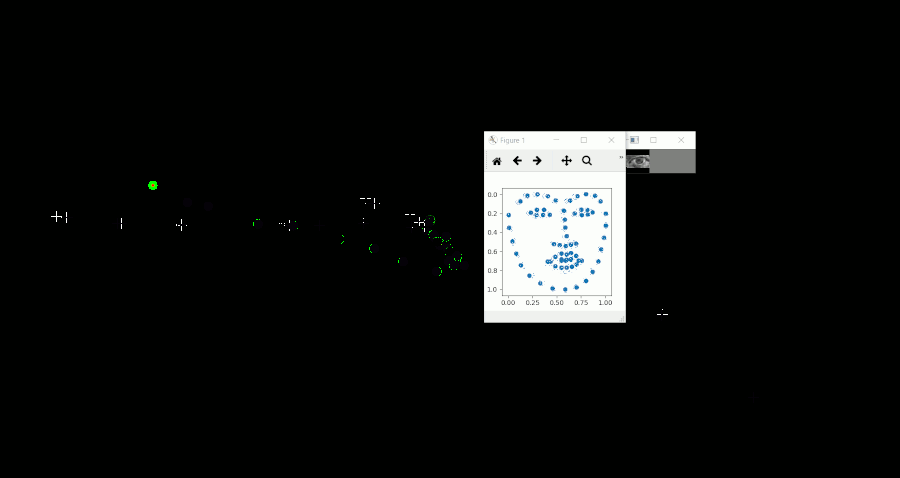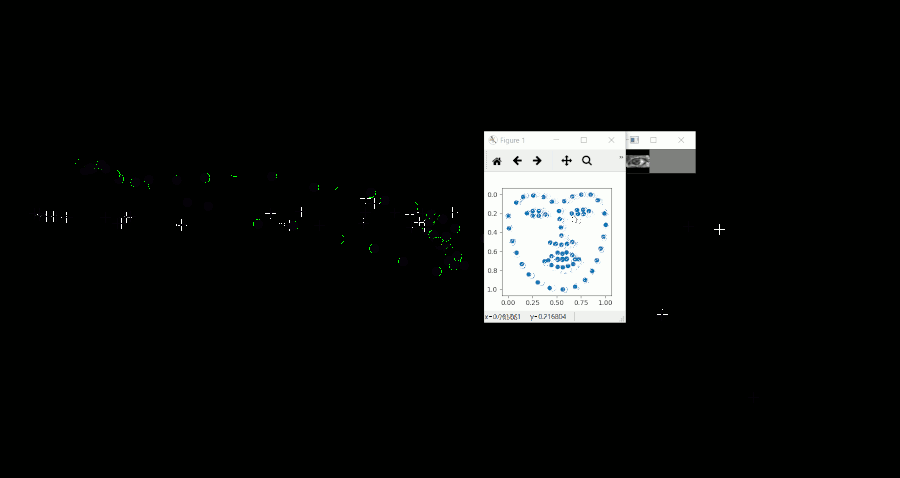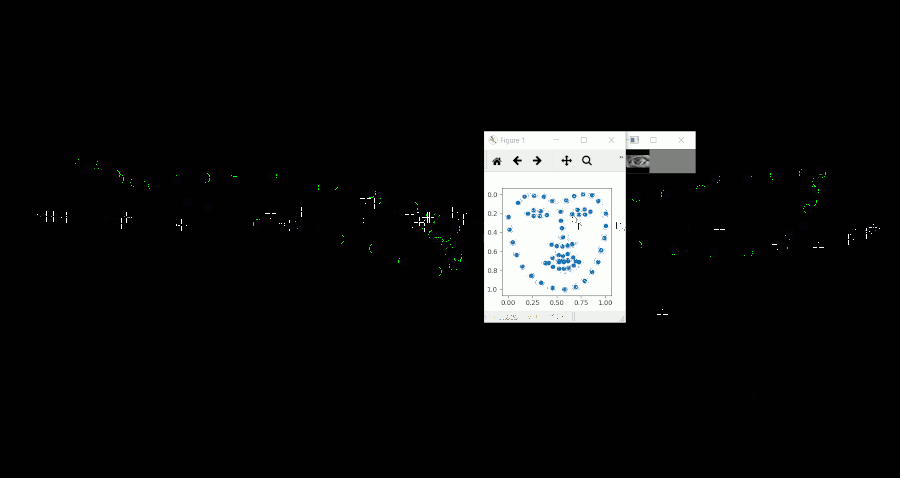
動作イメージ
マウスを追いかける形で左右に視線を移動しており、その際に推論した視線座標を緑の円で表示しています。(Gif上に残像が残っているため、少し見づらいです)
処理イメージ
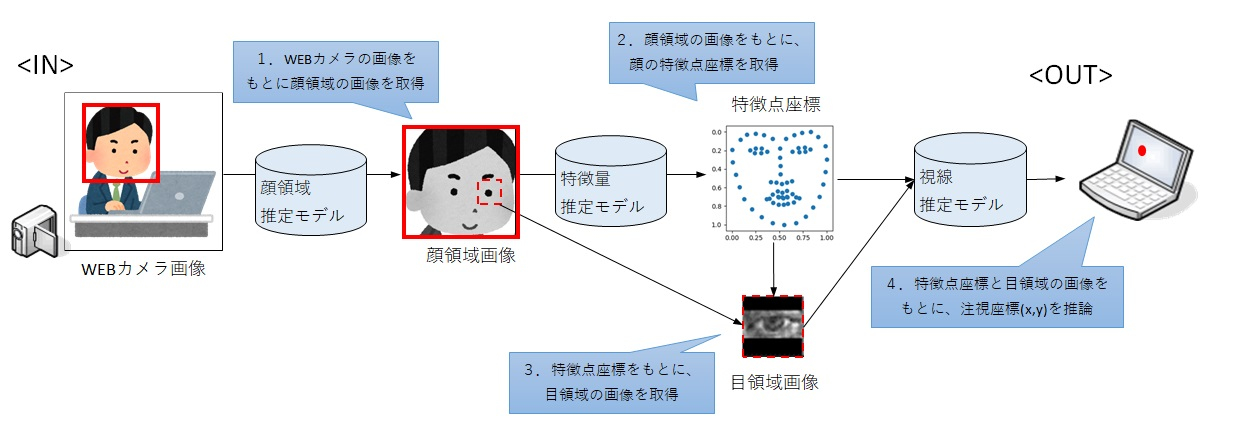
こちらのモデルについては、もともとpython上で推論することを前提に作成したものですが、ブラウザ上で動かすことで、Webページ操作中のユーザの視線が分かれば、UI/UXのレベルアップに役立つと考えました。
例えば、マウスをクリックすることなく注視しているコンポーネントの詳細をポップアップするなど、より高いレベルのユーザ体験を提供できたり、注視位置をログとして保存/分析することでより効果的に広告やコンポーネントを配置することができるかもしれません。
モデル変換時に必要な作業
TensorFlow.jsではkerasのモデルを変換するためのコンバータが提供されているので、作成済のモデルをそのまま使うくらいの軽い気持ちでやってみたのですが、結果的にネットワークの構成変更と再学習が必要でした。 以下に、Kerasで作成したモデルをTensorFlow.jsで使うために必要だった作業を記載します。
1. 前処理がJavaScriptで実装できるか検証
学習したモデルをブラウザで動かす際には、これまでPythonで行っていた前処理がJavaScriptでも同じように実装できるか?という点が重要となります。
既存モデルの前処理の流れは以下の通りです。
既存モデルの前処理イメージ(Pythonで実装)
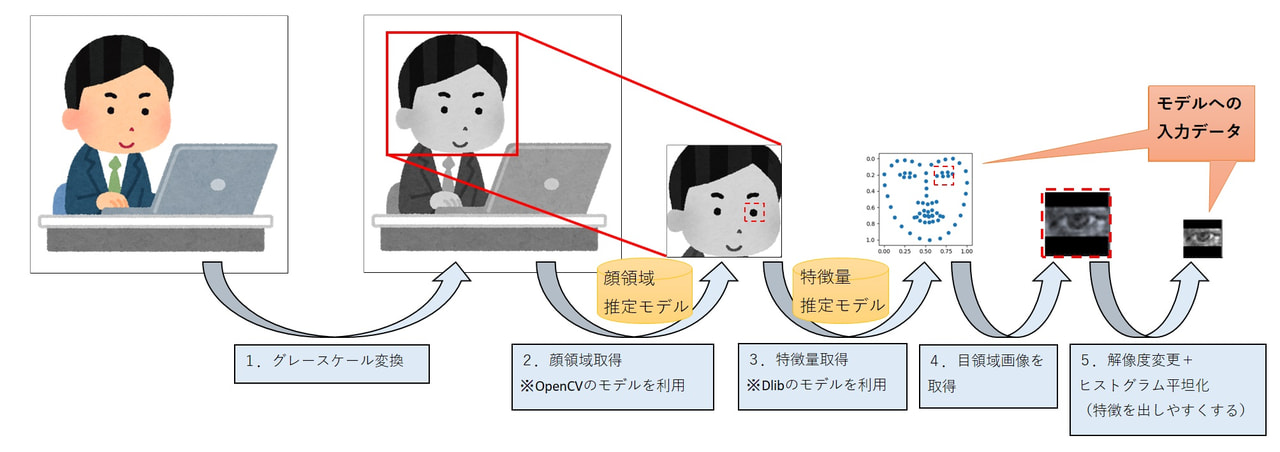
PythonではOpenCVを利用して画像処理を行っていましたが、同様の処理をJavaScriptで実装するにあたって、OpenCV.jsを利用しました。
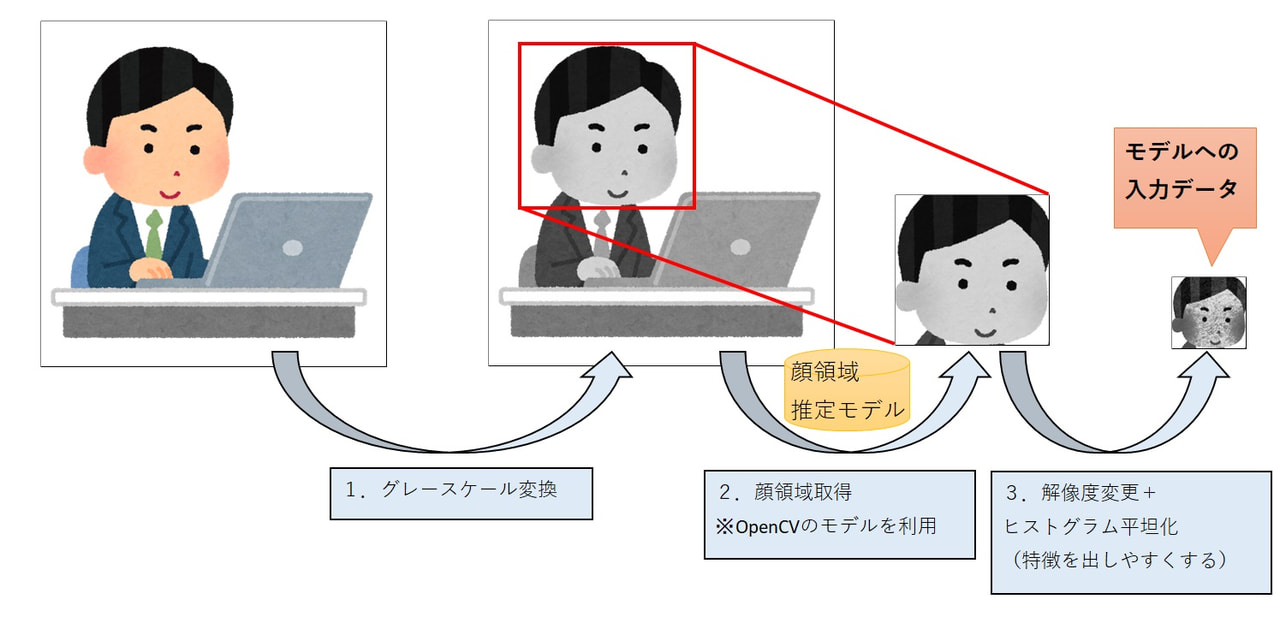
ただし、前処理内で別のモデル(Dlib)を用いて顔の特徴量を取得している箇所については実装が難しいと判断し、顔領域の画像のみを入力とするようにニューラルネットワーク構成も含めて変更しました。
新モデルの前処理イメージ(JavaScriptで実装)
2. ネットワーク構成の見直し
2.1. ネットワークの簡易化
前述の通り、入力データの変更に伴うネットワークの変更が必要だったため、合わせてネットワークをより簡略化し、モデルのファイルサイズとブラウザで推論する際の処理コストを抑えるように変更しました。精度をできるだけ保ったままモデルを軽量化するための方法としては、枝刈りや蒸留、量子化など様々な方法が研究されていますが、今回は単純に畳み込み層と全結合層を削減しています。
2.2. カスタム関数の除外
TensorFlow.jsのモデル変換処理では、Keras標準で提供されているレイヤーや関数のみサポートしています。
そのため、一部精度向上のためカスタマイズした損失関数を用いていましたが、Keras標準で提供されているもののみ利用するように変更しました。
モデル変換
以上の作業を行ったうえで、簡易化した視線検出モデルをkeras上で作成し、公式で提供されているモデルの変換処理を行うことで、TensorFlow.js用のモデルを取得しました。
モデルの変換はコマンド1行だけでできるため、非常に簡単です。
pip install tensorflowjs
tensorflowjs_converter --input_format=keras /tmp/model.h5(入力) /tmp/tfjs_model(出力先)
なお、公式のドキュメントに明記されてたわけではありませんが、使用するTensorFlow.jsとkerasのバージョンで変換時にエラーが起きないことは、前もって検証したほうがよいかと思います。
評価
以上の作業をしたうえで、実際にブラウザ上でモデルを動かしてみました。
雰囲気を出すため、推論した視線座標をもとにヒートマップを作成し、
埋め込み表示したホームページに重ね合わせています。
今回は、弊社ホームページ内の提供するソリューション・サービスの紹介ページを対象に、視線検出モデルがブラウザ上でも動くかどうか確認します。
基本的には左上から右下に流し見をしていますが、個人的に興味のある要素(特に右下)は意識して見つめるようにしました。
推論結果
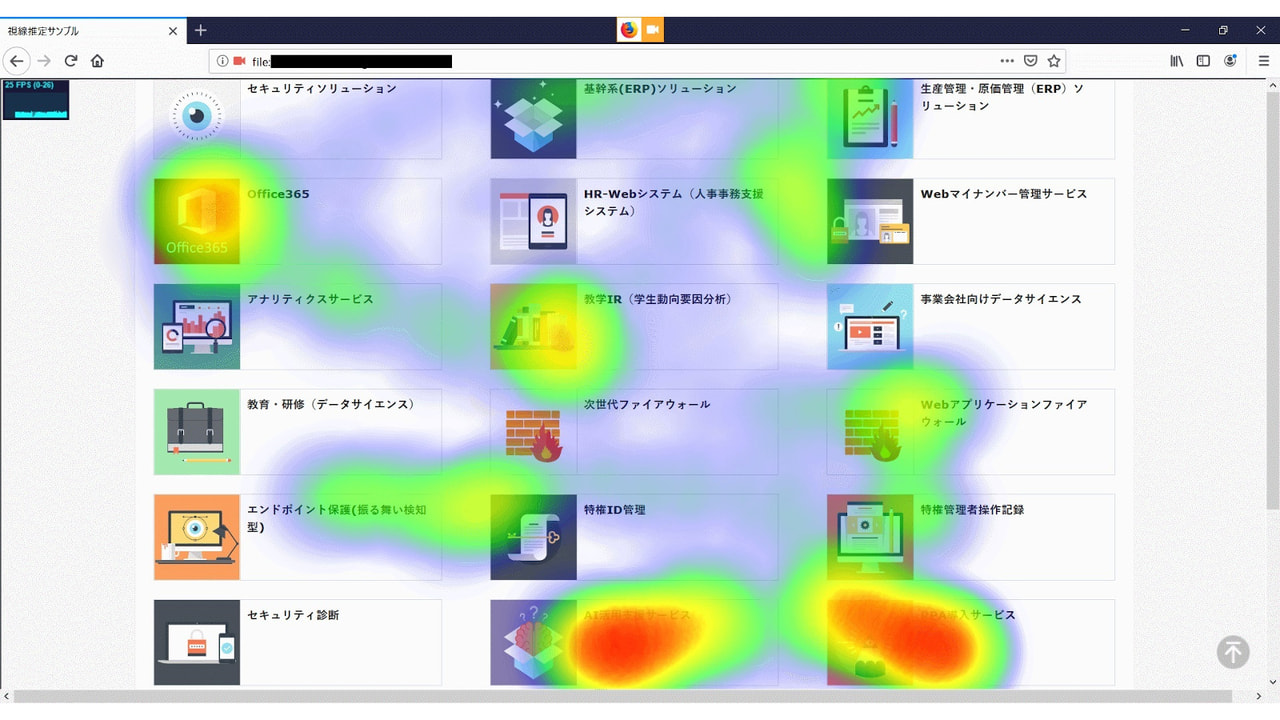
なんとなく右下の要素に視線が集まっていることが分かります。
視線検出モデルの精度が悪いため推論結果は現状かなり不安定ですが、環境としては問題なく動作しました。
続いて、実行速度の比較です。上限を設定しない状態で、各環境の平均fps(Frames Per Second)を確認しました。同様の処理(前処理+推論)に対して、1台の端末上でPython/JavaScriptで動かした場合の比較と、JavaScriptの場合には性能の違う2台のPCで比較しています。
端末のスペック
| 端末A(CPU、メモリのスペックが高い) | 端末B(社内標準スペック) | |
|
OS
|
Windows10
|
Windows10
|
|
CPU
|
Intel Core i7 8700@3.20Gz
|
Intel Core i5 6300@2.40Gz
|
|
GPU(内蔵)
|
Intel HD Graphics 630
|
Intel HD Graphics 520
|
|
物理メモリ
|
32G
|
8G
|
比較結果
|
端末
|
動作環境
|
平均fps(小数点切り捨て)
|
| 端末A |
Keras + Python
|
128 |
|
端末A
|
TensolFlow.js + JavaScript
|
25
|
| 端末B | TensolFlow.js + JavaScript | 20 |
1フレームごとに前処理+推論するような高コストな処理だったため、JavaScriptでは処理が重くなると予想していましたが、WebGLと内蔵GPUの恩恵もあり、標準スペックのPCでも20fps程度で処理できていました。一般的な映画のフレームレートは24fpsといわれているため、用途を考えると十分な速度といえます。
オリジナルのTensorFlowやKerasでは、GPUを利用するにあたってはCUDA環境のインストールやソースコードの修正が必要でしたが、環境を意識せずにGPUを活用できるのは非常に使い勝手が良いと感じました。
CUDA(Compute Unified Device Architecture):NVIDIAが開発・提供している、GPU向けの汎用並列コンピューティングプラットフォーム(並列コンピューティングアーキテクチャ)およびプログラミングモデル
(出典元:Wikipedia)
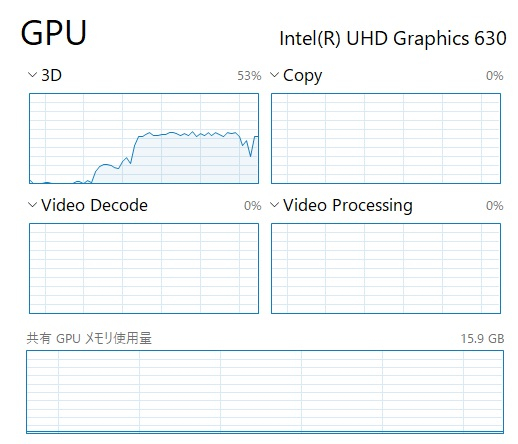
なお、動作中のGPUリソースの利用率は50%程度でした。
動作中のGPUリソース
推論結果(GIF)
動作のイメージは以下の通りです。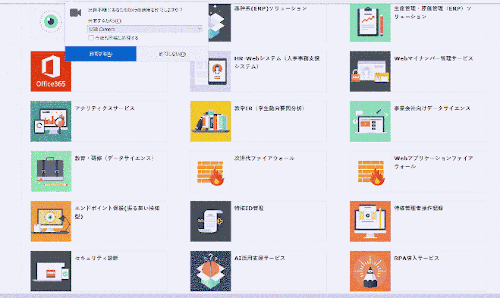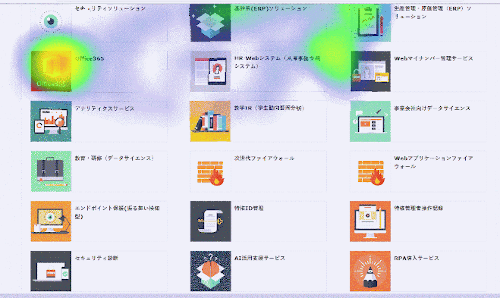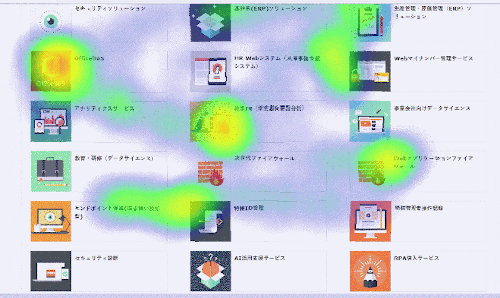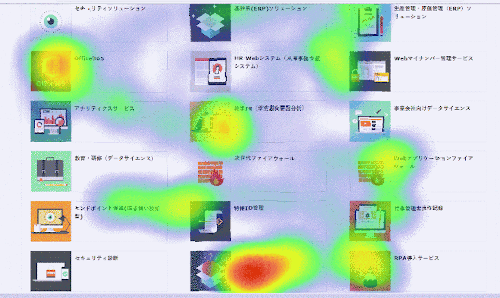
まとめ
本記事では、Kerasで作成したディープラーニングモデルをTensorFlow.jsを用いてブラウザ上で動かした際の注意点をまとめ、推論性能を確認しました。
サーバサイドでの推論に比べブラウザ上で推論することで、サイズが大きかったり個人情報を含むようなデータをインターネットに流す必要がなくなるメリットがあります。
前処理用ライブラリがまだ整っていなかったり、ページサイズや処理遅延の問題はありますが、昨今のJavaScript人気に伴うライブラリの拡充、ネットワークの高速化やWebAssemblyのような処理高速化技術の登場にともない、徐々に改善されていくでしょう。
ブラウザでの処理は環境差異が非常に大きいため、システムの要件を満たす実装ができるかは慎重に判断する必要がありますが、選択肢の一つとして押さえておきたい技術だと感じました。
なお、今回は視線を推論するにあたり自分の環境専用のモデルを自作しましたが、より汎用性のある視線計測用のJavaScriptライブラリとしてWebGazer.jsというOSSが存在します。デモもありますので、もし興味があればお試しください。
最後に、使用したライブラリとソースコードは以下の通りです。
使用ライブラリ
| 名称 | バージョン | 用途 |
| TensorFlow.js | 1.0.0 | ディープラーニングによる推論用 |
| OpenCV.js | 3.4.8-pre | 画像処理用 |
| heatmap.js | 2.0.5 | ヒートマップ描画用 |
| Stats.js | 0.17.0 | FPS計測、描画用 |
ソースコード(主要箇所のみ)
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>視線検出サンプル</title>
</head>
<body style="margin: 0px;">
<div style="position:relative;">
<iframe style="position:absolute;border:none;width:100vw;height:100vh;z-index=5;" src="https://www.dcs.co.jp/"></iframe>
<div id="heatmapContainer" style="position:absolute;width:100vw;height:100vh;z-index=1;"></div>
</div>
<div>
<p>デバッグ領域</p>
<table cellpadding="0" cellspacing="0" width="0" border="0">
<tr>
<td><video id="videoInput" width=320 height=240></video></td>
<td><canvas id="canvasOutput" width=320 height=240></canvas></td>
</tr>
</table>
</div>
<!-- TensorFlow.jsの読込 -->
<script src="tf.min.js"></script>
<!-- Stats.jsの読込 -->
<script src="stats.min.js"></script>
<!-- heatmap.jsの読込 -->
<script src="heatmap.min.js"></script>
<script src="utils.js"></script>
<script type="text/JavaScript">
// OpenCV処理ユーティリティ読込
const utils = new Utils();
// WEBカメラ画像取得用
const videoInput = document.getElementById('videoInput');
// デバック表示用
const canvasOutput = document.getElementById('canvasOutput');
// FPS表示用
let stats = new Stats();
stats.showPanel(0);
document.body.appendChild(stats.dom);
// TensorFlow.jsのモデル読込
let model;
async function loadModel() {
model = await tf.loadLayersModel('./model.json');
};
loadModel();
// heatmap.jsの設定
const heatmap = h337.create({
container: document.getElementById('heatmapContainer'),
radius: 90,
blur: .9,
});
// 推論結果のブレを抑えるための移動平均フィルタ
const moveFilter = (function() {
const maxSize = 5;
const queue = new Array();
return {
getValue: function(newX, newY) {
queue.push({ x: newX, y: newY });
if (queue.length > maxSize) { queue.shift(); }
let sumX = 0;
let sumY = 0;
queue.forEach(function(val) {
sumX += val.x
sumY += val.y
});
return { x: sumX / queue.length, y: sumY / queue.length };
},
show: function() { return queue; }
};
})();
function onVideoStarted() {
// OpenCV処理用変数の定義(終了処理内で明示的にdelete()が必要)
let src = new cv.Mat(videoInput.height, videoInput.width, cv.CV_8UC4);
let dst = new cv.Mat(videoInput.height, videoInput.width, cv.CV_8UC4);
let gray = new cv.Mat();
let cap = new cv.VideoCapture(videoInput);
let faces = new cv.RectVector();
// 顔認識モデルの読込
const classifier = new cv.CascadeClassifier();
classifier.load('haarcascade_frontalface_default.xml');
// フレーム毎の処理
function processVideo() {
stats.begin();
cap.read(src);
src.copyTo(dst);
// グレースケール変換
cv.cvtColor(dst, gray, cv.COLOR_RGBA2GRAY, 0);
// 顔認識実行
classifier.detectMultiScale(gray, faces, 1.1, 3, 0, new cv.Size(70, 70));
// 顔認識した場合のみ
if (faces.size() > 0) {
const face = faces.get(0);
// 顔領域の切り取り
const rect = new cv.Rect(face.x, face.y, face.width, face.height);
dst = gray.roi(rect);
// 解像度を50*50にリサイズ
const dsize = new cv.Size(50, 50);
cv.resize(dst, dst, dsize, 0, 0, cv.INTER_AREA);
// ヒストグラム平坦化
cv.equalizeHist(dst, dst);
const tileGridSize = new cv.Size(8, 8);
const clahe = new cv.CLAHE(40, tileGridSize);
clahe.apply(dst, dst);
// 処理結果をデバッグ用領域に描画
cv.imshow('canvasOutput', dst);
// 推論処理
// GPUメモリ上のテンソルはGC対象外のため明示的に開放する必要がある
const prediction = tf.tidy(() => {
const offset = tf.scalar(255); // 0~255を0~1へ範囲変換
const input = tf.tensor(dst.data).div(offset).reshape([50, 50, 1]).expandDims();
return model.predict(input).dataSync();
});
// 推論結果はx軸、y軸ともに0~1の範囲で出力されるため、ウィンドウサイズを掛ける
const filtered = moveFilter.getValue(prediction[0] * window.parent.screen.width, prediction[1] * window.parent.screen.height)
// ヒートマップに描画
heatmap.addData({ x: filtered.x, y: filtered.y, value: 1 });
stats.end();
}
requestAnimationFrame(processVideo);
};
requestAnimationFrame(processVideo);
}
// OpenCV読込後の初期処理
utils.loadOpenCv(() => {
// pre-trainingファイルの読込
const faceCascadeFile = 'haarcascade_frontalface_default.xml';
utils.createFileFromUrl(faceCascadeFile, faceCascadeFile, () => {
console.log("loaded");
});
utils.startCamera('qvga', onVideoStarted, 'videoInput');
});
</script>
</body>
</html>
