
はじめに
三菱総研DCSデータサイエンス事業部の坂田です。
最近は新型コロナウィルス(COVID-19)の感染対策のため、テレワークで業務を行うようになった方も多いのではないでしょうか?
データ分析に携わる身として、改めてコロナ影響に対してどう向き合っていくべきか整理してみましたのでご紹介したいと思います。普段、データ分析に携わっていない方にもお読みいただけるよう、数式や統計の手法については深く触れないような構成になっておりますので、お気軽にお読みいただければと思います。
COVID-19の各業界への影響
日本国内で新型コロナウィルスの感染が拡大し始めてからの数か月間、様々な変化を実感した方が多いのではないでしょうか。生活面では、生活用品(マスクやアルコール除菌類、トイレットペーパーなど)や一部の食料品が不足し、入手困難となった時期もありましたね。また、労働面では、緊急事態宣言による外出自粛要請があったため、テレワークや自宅待機、休業を余儀なくされた方も多かったと思います。
これらのコロナショックによる経済への影響は大きなものとなりました。 実際に、内閣府が公表している「景気ウォッチャー調査」[1]でも、現状の街中の景況感を示すDI値(Diffusion Index, 景気動向指数)が2020年4月にはすべての業界で大幅に低下しています。これは2008年から2009年にかけて起こったリーマンショックや2011年の東日本大震災の時期よりも下回り、過去最低の更新となりました(図1)。
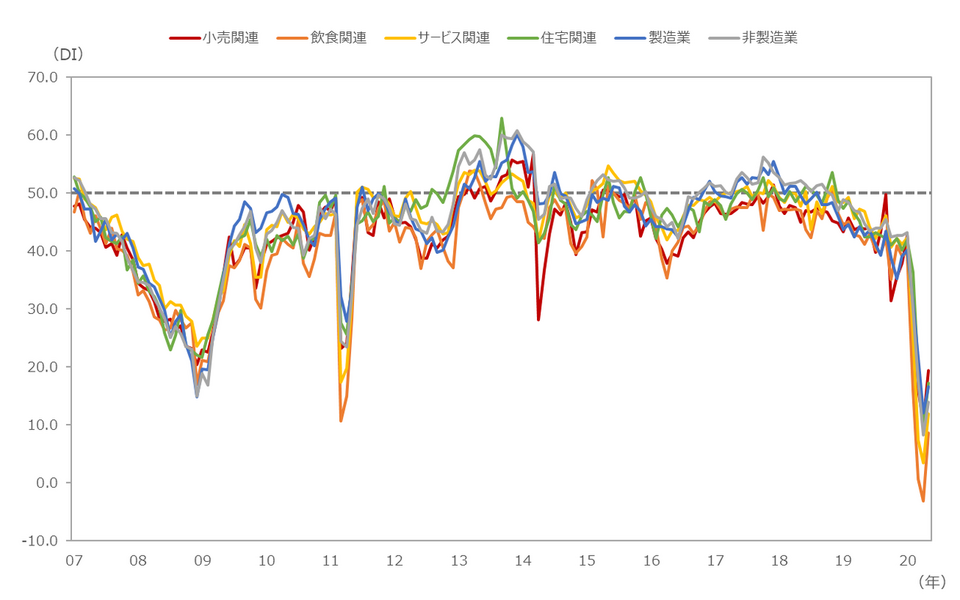 図1 業界分類別 景気の現状判断DI(2007年~)
図1 業界分類別 景気の現状判断DI(2007年~)
データの変化に伴う対応
コロナショックによる影響は、私たちが携わっているデータ分析の分野においても例外ではありません。
未だかつてない規模で全世界的に襲い掛かったコロナショックは、影響範囲の見極めが非常に難しいです。逆説的には、影響を見極めない限り、次の手立てを考えられないともいえます。
「今までの分析に影響はないか」「何か対応する必要はないか」と頭を悩ませている方も少なくないのではないでしょうか。
「どうすればよいのか」という問いにお答えするのは難しいですが、「何をすればよいのか」という問いには明確な答えがあります。それは「影響を見極めること」です。
自分の目の前にある分析結果や予測モデルが、コロナ禍でどのような影響を受けているのか(場合によっては影響がないこと)を一つ一つ確かめクリアにしていくことが、分析におけるコロナ対応の第一歩なのではないでしょうか。
身近な例:コロナ前後の先輩のビール飲酒量モデル
Ⅰ. 本当にコロナショックの影響ってあるの?
実際に、コロナショックでモデルに対しどのような影響が起こりえるのかをイメージしていただくため、私の身近で発生した事例をご紹介します。
私の部署にはお酒をこよなく愛し、みんなでわいわい飲むことが大好きな先輩がいます。その先輩が自身のビールの飲酒量予測モデルを趣味で作成していたので、今回はこちらを見ていきましょう。
図2が2019年2月~2019年6月の結果、図3がコロナショック後を含む2020年2月~2020年5月の結果です。グラフのブルー線が実測値(実際に飲んだ量)、オレンジ線が予測値(モデルが予測した量)です。
なお、今回の予測モデルの概要は以下の通りです。
- 予測モデル:状態空間モデル(Local Level Model/seasonal7)
- ターゲット:ビールの飲酒量(ml)※ビール以外のアルコール類は含まない
- 特徴量(外生変数):「大人数の宴会があったか」「ワインや日本酒を飲んだか」「セミナー・勉強会に参加したか」「社内サークル活動に参加したか」「習い事に参加したか」
- 学習期間:2019年2月~2019年4月
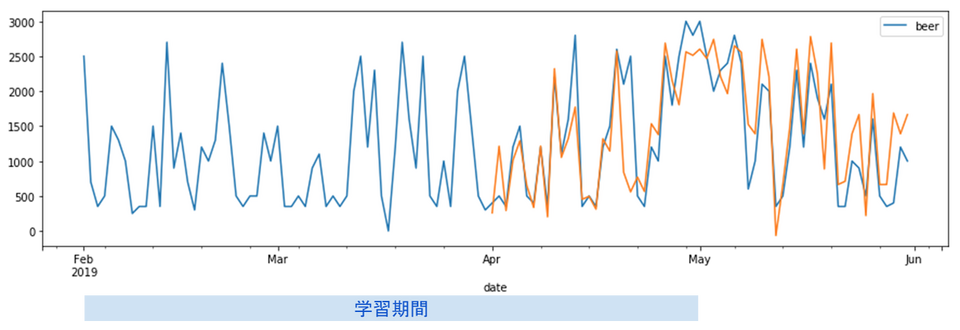 図2 コロナショックより1年前の予測結果
図2 コロナショックより1年前の予測結果
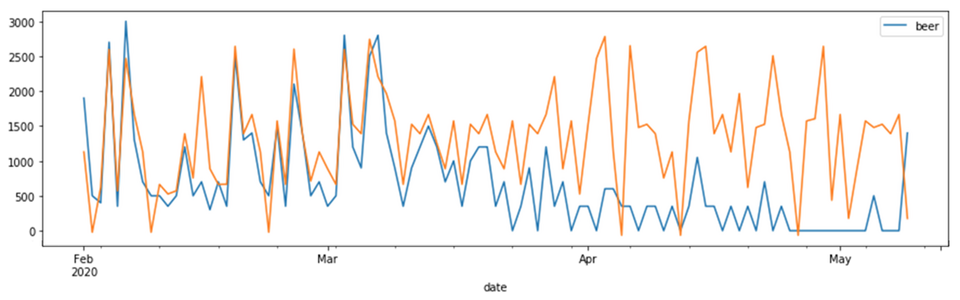 図3 コロナショック後の予測結果
図3 コロナショック後の予測結果
この結果を見て分かる通り、コロナショックが起きた2020年3月中旬頃から少しずつ予測精度が劣化し始め、2020年4月以降は予測が大幅に外れるようになっています。新型コロナウィルスの感染が拡大し、外出や飲み会の自粛の動きが広がったことに伴い、先輩の何かしらの生活習慣が変化してデータの内容が変わったことは明らかです。では、具体的に先輩にどんな変化が起こり、このような精度劣化に陥ったのか確認していきましょう。
Ⅱ. コロナショックにより先輩に何が!?
私は最初に「外出自粛により飲み会が減り、お酒を飲む量自体が減った」という仮説を立ててみました。この仮説は部分的には正解でしたが、実はこれはあまり大きな原因ではありませんでした。
実際に先輩にヒアリングを行ったところ、色々な事実が見えてきたので、コロナショック後の予測結果と先輩の行動を照らし合わせた結果を図4に示します。
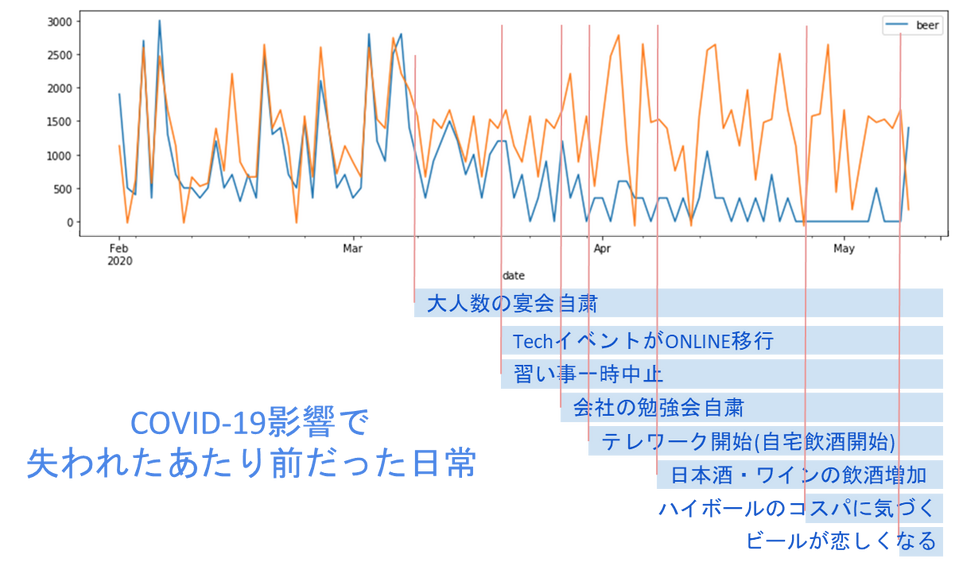 図4 コロナショックに伴う生活習慣の変化
図4 コロナショックに伴う生活習慣の変化
2020年3月中旬頃から飲み会のトリガーとなっていたイベントが減少、そして4月からのテレワーク開始による家飲みへのシフトがビールの飲酒量を減らしています。
ここまでは私の予想通りですね。
しかし、先輩によると毎日のようにオンライン飲み会をしていたそうです。当初はビールを飲んでいたものの、日を追うごとに食事に合わせてワインや日本酒をよく飲むようになり、4月下旬頃にはコストパフォーマンスのよいハイボールの魅力に気付いてその虜になったことが、ビールの飲酒量が減少したことの直接的な原因とのことでした。ちなみにコロナ以前にビールをよく飲んでいたのは、飲み放題の宴会だとビールが最も原価率が高くてお得だと思っていたからで、基本アルコールならなんでも好きなのだとか(5月中旬にはコストパフォーマンスに関係なくビールに戻ってきています)。
この事実、コロナショックの直接的な影響ばかりに気を取られていたら気付くことができないですよね。今回の事例は大げさな内容かもしれませんが、人の行動を分析して予測するという作業の中には、データだけでは見えてこない事実が多かれ少なかれ隠れていることもあります。
大事なのはデータと向き合うこと
さて、最後にここまでみてきたようなモデルの精度劣化を修正する上で、何をすればよいかを整理してみようと思います。モデルを修正する上での大枠の選択肢はそこまで多くないと感じています。
- 学習データの期間を見直す
- モデルのハイパーパラメータを見直す
- 使用する特徴量を見直す
- 分析手法(アルゴリズム)を見直す
問題はどの方法をとるかの方針の決定です。
まずは使用している特徴量について、それぞれの分布がどう変わったのか(1変数の解析)、2つの特徴量の関連性がどう変化したのか(2変数の解析)と影響を確認し、調査の方向性を定める等、地道な作業の積み重ねになってきます。
結局のところ、以下のようなデータ分析で行うべき基本的なタスクを行い、しっかりとデータと向き合うことが精度向上の一番の近道だったりします。
①分析データ準備
- 分析利用データの収集と選別
- データの内容確認とクリーニング
- 分析に必要な変数の新規作成・加工
②分析と評価
- 分析の実施・モデルの構築
- 分析結果の評価、精度向上のためのチューニング
- 効果検証・モニタリング方法の決定
また前章でも触れた通り、目の前のデータに集中していると「データだけではすべての事象を表現できない」ことをつい忘れがちです。データの外側に目を向けず、今あるデータから何かを導き出そうと必死になり、時間ばかりが過ぎていくことは少なくありません。
そのため、私たちデータ分析者はPCの前に座るだけでなく、実際にフィールドワークとして現地に足を運んだり、お客様と直接会話し、データだけでは分からない情報や専門知識を収集したりすることがとても大切です。
おわりに
分析の進め方にはいくつかの定石があるものの、決まった正解がないことが面白さでもあり、難しさでもあると感じています。分析の進め方を身に着けるには、日々の業務の中でいくつかの壁にぶつかり、そこから学んだ知識の積み重ねが成長への近道だと思います。
しかし、皆さんの中には壁にぶつかってばかりではいられず、体系立てて分析を学ぶ機会や、分析の進め方を見直す機会が欲しい方もいらっしゃるのではないでしょうか。
弊社ではそんな方に向けて、データ分析研修のメニューもご用意しております。ご興味がありましたら、是非お問い合わせいただければと思います。


最後は宣伝っぽくなってしまいましたが、DXやAIといったバズワードの裏側では、地道な分析の経験やノウハウが必要不可欠です。私たちもこのコロナという状況を経て、分析に対する考え方を基本に立ち返り改めて整理しなければと感じる機会となりました。
本稿が、同じような業務に携わっている方々の何かの参考になれば幸いです。
参考文献
[1] 内閣府「景気ウォッチャー調査」
